一种自我进化的、可互操作的分布式应用系统
秦春林
Reality World是一个以互操作性为核心目标的分布式系统和架构,它的愿景是构造一个无边的数字世界,使得任何人都可以向这个系统动态添加新的子程序,这些子程序可以和其它子程序任意交互,这个系统可以像生物系统一样自我进化,从而通过复杂系统的机制涌现出更加智能、丰富和个性化的数字世界体验。
摘要
近年来,随着区块链、元宇宙以及大模型的发展,数字世界的构建逻辑和使用形态都发生了很大变化。然而总体而言,目前并没有比较成熟的专门面向这些新型特征应用的底层架构,甚至还没有形成比较清晰和统一的思路,比如这种架构应该有哪些新的特征、形态以及设计目标。尝试构建这样的一套新的方法体系是非常复杂的,我认为核心的难点在于很难单从软件架构的视角去解决这一问题。比如元宇宙类应用,表面上看我们可以在现有的引擎架构上去构建,然后元宇宙背后的核心逻辑是互操作性,它要求来自不同开发者创建的应用之间能够进行交互,从而提供更动态、多元和个性化的数字化体验,然而互操作性和传统的软件开发逻辑是相悖的。再比如多智能体类应用,最近更多的工作意识到这类应用的逻辑更可能需要很多具有独立功能的小智能体进行相互协作来实现,这种多智能体相互协作的逻辑跟复杂系统的行为是类似的,然而我们当前的编程模式并没有针对这样的思想进行设计。从上面的论述可以看出,未来数字世界的软件构造方法,需要考虑更多的跨领域知识体系。本文正是通过对传统的软件架构方法(如面向对象和函数式编程模型)、编程语言及其编译过程和链接过程、区块链、复杂系统、游戏应用架构等跨领域知识进行系统分析,结合这些新型应用的特征,提出了一套系统的架构体系,它包括清晰的设计原则、目标、方法哲学,以及一个包含核心机制的源代码实现。希望此工作可以对未来数字世界基础架构的设计、研究和开发提供有益的指引。
问题
近几年,数字世界的形态发生着巨大的变化,一方面似乎是面对互联网红利的逐渐下降,人们需要新的科技引爆点;但另一方面,这些新的概念也在某种程度上折射出一个信息:那就是我们生活中的数字化还不够彻底,还不够丰富,还没有完全释放它全部的力量。
例如在Web 3.0的概念中,我们希望我们的隐私和资产能够不被少数中心化的实体所控制;在元宇宙的概念中,我们希望任何人能够进行更自由地创造数字内容,并使我们的数字分身连同我们的很多能力能够在跨域多个虚拟世界中进行互操作,从而提供接近现实世界的数字生活体验;而在大模型应用中,随着大模型对人类任意指令的语义理解,固定的软件逻辑似乎无法应付这种逻辑复杂度,我们希望应用内部能够更智能地协调和调度正确的功能来解决任意的问题,而不是像过去那样提供固定结构和功能的软件。
所有这些新的需求可能都意味着我们需要新的思维和方法来构建应用,而人们自然是希望基于现有的软件工程体系,能够进行少量的架构设计,来实现上述这些应用的开发。本节我们就来看几个基本的问题,从而理解我们现行的体系在解决这些问题方面会遇到哪些挑战,这些问题的理解也为后面的架构设计提供重要的依据。
当然,这只是几个典型问题,本文后面的内容还会讨论更多的相关问题。
去中心化和数据安全
我们现代整个构建软件的方法体系,不管是底层的编程语言及其提供的一些编程模式,如面向对象或函数式编程,还是中间一些帮助构建各种应用的工具,如游戏引擎和各种开发框架,都是基于这样一个前提或假设:即程序拥有所有的权力,程序可以控制和访问一切数据,不管是内存中的数据,还是应用本地持久化存储的数据,还是应用存储到云端的数据。这样做的目的是简化编程模型,这种简化的思想体现在两个层面:
- 操作系统为每个应用分配独立的内存空间,因此通过这种简单的内存隔离就可以保证应用的数据安全
- 将应用内产生的用户数据的管理交给开发商,由他们负责保证数据的安全
从上面的机制可以看出,尽管现在各国都应相应的合规法律来保护用户的隐私数据不能被非法上传或使用,但实际在操作层面,很多数据的交互涉及到功能层面,例如需要在云端与来自其它用户的数据进行计算,所以很多数据其实很难界定,因此我们的隐私数据一般只包含部分数据,而还有很多应用执行过程中产生的数据也是对用户而言很重要的。
由于应用程序对数据的天生的权限,使得软件开发商天然的成为一个中心化的实体,掌控着所有用户的数据。尽管很多时候,这种中心化的管理带来了很多便利和效率,但是对于用户而言损失则是很大的,除了数据被非常使用的风险,还有包括在平台获取合法收益时不透明性,没有话语权,同时出于竞争考虑,一个应用的数据对同一个用户的其它应用通常是无法互操作的,而这种互操作很多时候对用户来说是很有价值的。

这里面的根本问题,我觉得是这个编程模型的问题,它将程序的功能和程序执行过程中产生的数据关联在一起,彼此无法分开,如上图(a)所示。想想我们现实生活中的经济模式,一个厂商生产了某件商品,用户购买商品之后,除了简单的售后服务关系,用户和厂商之间就没有其它关系,该商品后续生产的物品都有用户自己拥有,用户可以将这些物品用于任意自己的意图。
所以,为了更好地保护用户的权益,我们需要一种天生能够将软件的数据和功能分开的机制,本文就会提出一种机制,使得开发者使用类似现有的方法进行软件开发,但是其产生的数据确实天生由用户控制的,换句话说,即使是同一个应用产生的数据,用户都可以在后续的操作中禁止该应用对之前产生数据的访问,而且这种控制方式非常简单,如上图(b)所示。
这种编程模式的改变,会对应用的形态造成非常深刻的影响,它也会带来更多新的技术上的可能性,使得我们可以构建更加复杂丰富的应用。这些特性也正是元宇宙和Web 3.0数字经济的构建所需要的基本特性:它使得互操作变得简单和可能。
互操作和用户内容创作
尽管元宇宙还没有明确的定义和形态,但是它的一些基本特性也慢慢被人们接受,比如虚拟与现实的结合,用户生成内容,去中心化和开放性,以及数字身份,社交和经济系统等等。元宇宙看起来包括了Web 3.0的思想,但是它可能并不寻求所有的数据都保存在区块链上,因为那样在理论上根本无法满足人们的使用体验需求。
从上面这些特性中,我们可以看出它们对现行的技术体系都会带来很大的挑战。其中关于去中心化和价值交易部分可以由区块链技术来实现,从本文后面也可以看出,互操作性和开放性方面也可以由我们上一节提出的程序架构来实现,然而对于用户创造的程序内容本身,依然存在比较大的挑战。
真实世界的经济系统的核心,是这个经济系统的大部分参与者都在参与经济生产,通过经济生产创造价值,然后才是交易。想想我们每个人都在上班,创造不同的产品,从事经济生产,然后人们用赚取的工资通过交易来换取其他人生产的有价值的东西,这个系统中的经济价值主要是由所有人一起创造出来的。
一个繁荣的数字经济系统也不例外,然而我们看现在的数字经济,从事生产活动的人是极少的,根据Deverloper Nation网站统计,2021年世界上只有2430万开发者,预计到2030年也只有4500万开发者,这在人类人口数量中不足0.5%,如下图所示:

尽管在今年大模型在代码生成上表现出极大的潜力,甚至微软CEO Satya Nadella也提出未来可能借助大模型的能力,使得10亿人可以成为开发人员:
“I mean, there can be a billion developers. In fact, the world needs a billion developers… So the idea that this is actually a democratizing tool to make access to new technology and access to new knowledge easier, so that the ramp-up on the learning curve is easier.”
然而随着大模型在辅助代码编程方面的使用,例如Github Copilot,我们也逐渐意识到大模型虽然能够在一定程度上提升开发效率,但是它对专业人员的要求依然很高,换句话说,依然只有比较专业的开发人员才可以更好地使用它。这还只是考虑它在局部代码模块,例如单个函数级的代码生成,还不包括更复杂的程序结构和上下文逻辑管理。实际上如今的大模型在理论上主要以预测前后相关的线性序列来实现内容生成,这种理论在针对程序结构这种非线性、组合式的复杂任务上似乎存在一定的理论限制,如 Faith and Fate:Limits of Transformers on Compositionality 这篇研究工作指出。
除了编程语言本身,元宇宙类的应用还要求更多的动态性,以及更重要的是在一个宿主程序中安全运行第三方子程序的能力,这会带来非常大的安全性挑战,尽管我们现在有一些如Web Assembly等包含的沙盒技术可以在理论上实现这些机制,但是在根据层面还没有比较简易可靠的框架可以使用,因为这种框架还需要协调应用程序本身的构造和运行机制。
多智能体相互协作机制
多智能体(Multi-Agents)是AI领域现在比较热门的一个方向。大模型对于自然语言的理解和对话能力,使得一些借助大模型内部的知识来完成推理和规划的Agent应用广受关注,例如AutoGPT、Generative Agents、BabyAGI等等。然而人们实际在开发中,也由于逐渐受限于大模型的能力,使得单纯简单依靠大模型来推理的Agent会比较难以落地,实际的Agent开发往往还是要涉及大量的逻辑开发,当然其中的逻辑交互主要涉及的是自然语言,也正是受限于大模型在自然语言理解方面的鲁棒性,实际的开发都是需要设置大量精巧的提示词工程才能达到比较好的性能。
不管是受限于单一Agent在记忆管理方面的不可靠性,还是由于越来越复杂的交互逻辑使得Agent开发和管理的复杂度逐渐增加,越来越多的工作将焦点转移到了多智能体系统上,即通过在一个共享的环境中让多个具有不同决策能力的Agent共同协作来完成一些指定的事情。尽管我们可以使用传统的方法来开发这类多智能体系统,例如基于LangChain,然而实际上多智能体协作机制有一些新的技术特征。
多智能体主要的技术特征是动态性,由于Agent的数量极多,成百甚至上千,那么这类系统要具备动态的能力,能够动态添加或移除一些Agent,同时具有较好的容错性,其中的某些Agent出现运行错误时,系统可能缺乏某些方面的能力,但是不影响其它能力的正常运行,在这些出现运行错误的Agent恢复运行后整个系统能够动态容纳该能力。
这看起来像是Actor模型尝试解决的问题,Erlang 是Actor模型比较有知名度的代表,如果我们把一个Agent比作一个线程或者Actor,那么Actor模型的工作机制似乎就可以实现多智能体交互的需求。开源项目 Chidori 也正是基于该理念的一个多智能体开源项目。在这类架构中,单个Agent会订阅某类信息,然后系统会维护这类信息的分发,使得一旦有Agent发出了某类信息,订阅该信息的Agent就会得到响应,信息本身充当了交互的接口和机制。
相对于多智能体的需求,这类架构还存在着两点不足:
- 缺乏数据互操作的机制或Agent之间通信的协议,每个Agent之间主要是通过字符串进行通信,这样保证Agent和Agent之间的功能解耦。然而这样的隐式协议通常不便于Agent之间的协作,特别是来自不同的开发者之间的Agent,它们在通信格式上没有显式的保障机制。此外,Agent相较于一个Actor算是一个比较大的线程,内部本身还包括很复杂的逻辑,也就意味着Agent内部可能还包括着大量需要获取用户数据的逻辑,这其中有些数据是来自其它程序的定义,这也需要互操作性的支持。
- 缺乏开发这类应用系统的方法论。多智能体协作类似于一种复杂系统,复杂系统的一个典型特征是它的行为或功能是不可预期的,它们是靠很多逻辑简单的子系统相互作用涌现出现的,这就意味着我们不光是需要开发这种系统的工具,还需要一套系统的方法论来帮助我们测试或预测系统的功能行为,使之符合用户的预期,否则复杂系统在大部分情况下可能会表现出未知的行为。
第一个问题也是传统简单的Actor模型在复杂项目中会遇到的问题,传统的Actor模型一般有两个假设:一是Actor足够小,甚至几乎就是一个函数;二是Actor函数功能本身类似纯函数,这样它内部就没有状态,整个问题就简化了很多。这种模型针对那种只是业务量多、但是业务之间相对独立的业务场景是比较合适的,例如Erlang本身针对的电信业务场景,以及Web服务类应用。但是针对更一般的业务场景,业务之间都穿插着大量的数据交互,这种交互没有比较简单的规则,所以我们传统的程序开发,最复杂的部分,也许就是这种数据管理的复杂性:每个业务函数本身的逻辑可能是比较清晰的,但是为了执行这个函数以及为了知道什么时候需要执行这个函数,我们需要从整个程序到处去寻找条件,例如来自各个地方的上下文数据,和各个逻辑的前置条件,这通常没有一个简单的解决方案,这可能也是编程学习门槛中相对编程语言语法本身更复杂的部分。
在后面的介绍中,我们将通过类型系统以及对应的互操作机制,来解决这个问题。同时也会通过更深刻地洞察和借鉴复杂系统的一些思路来解决第二个问题。
相关知识
本节我们会简单介绍一些零碎的已有相关知识,当然这里仅介绍它们的一些基本概念和思路,其目的是为了理解其中的思想,从而更好地理解我们的架构怎样去采用这些思想,又做出了什么调整,为什么要做出这样的调整,以及做出了这些调整之后带来了什么新的变化。
互操作性
互操作性的 定义 如下:
Interoperability is a characteristic of a product or system to work with other products or systems.
由定义可以看出,互操作的本意在程序的环境下就是函数调用的能力,但互操作性大多是指两个相对比较隔离或者不同语言的系统之间的函数调用,内部的函数或编译到程序内部的第三方函数调用则不需要强调它的互操作性意义。例如宿主程序与动态脚本程序之间的互操作,例如C++与C或者Rust与C之间的互操作,甚至一个虚拟机支持的多个语言编程的程序之间的调用或通信。在这类情况下,被调函数的类型是无法被编码到程序中的,这通常需要程序内部实现一个对应的内部类型,然后相互之间通过某种格式的字符串来传递信息。所以互操作通常是和标准相关的:
If two or more systems use common data formats and communication protocolsand are capable of communicating with each other, they exhibitsyntactic interoperability. XML and SQL are examples of common data formats and protocols.
传统的软件世界通过一些标准来建立互操作的基础,例如HTML、XML、SQL、USD等等,比如Nvidia就基于USD构建了Omniverse,由于其对USD格式的良好支持,使得其可以兼容大部分的内容制作工具,就构建起一个以Omniverse为中心的内容和应用生态。
Tim在2019年的演讲《Foundational principles & technologies for the metaverse》中大量提到了标准,为了实现多个独立应用程序之间的协作,那么必然要建立大量的标准,有了这些标准,互操作就变得简单,例如《堡垒之夜》现在的Creative模式实际上已经有了很多标准,比如一个物体怎么摆放在环境中,并可以被其他玩家交互,这都是可以由Device来定义的,这实际上就是一种形式的标准或者接口,只要遵循这些标准,则可以很轻易的与其他的环境进行交互。
然而这种基于文本标准的方式仍然有一些缺陷,例如其数量是非常少的,通常必须等一个组织对一个标准有一定影响力之后才能形成实时上的标准,被更多的三方兼容和支持。想想现实世界,各个实体之间的交互和联系几乎是无所不在的,例如一个人在路边新开了一家饭店,路过的人随时可以进去吃饭,不会说还要先接一下饭店定义的一个接口。而程序是必须有严格的逻辑的,比如保证地址、参数和接口的一致性才能进行互操作,这给软件世界的互操作带来了一定的困难。我们应用程序开发的流程通常都是先定义内部数据结构,实现软件功能之后,再以一定的形式封装一些接口,并以某种方式公布出来,由感兴趣的三方去集成。然而实际上有大量的软件开发者是没有精力或者能力去提供这些接口的。想象一个场景:开发者A开发了某个应用给用户新增了一种新的健康类的数据信息,这个数据本来是属于用户的,这个时候用户想要用这个数据来实现另一个事情,TA想自己或者说让其他开发者B帮助开发一个应用来使用这些数据,这种情况下通常是做不到的,因为开发者A可能并没有太多动力去提供这个接口,因为TA可能要耗费很大的精力,除非平台提供一些这种非常便利的机制使得TA可以很轻易地暴露出来。
其实更深刻一点理解,互操作问题其实是一个软件碎片化的问题。传统的软件开发都是先开发内部数据结构和数据存储,然后在必要的时候再把API包装使用某种形式的标准包装成外部接口,这样就造成碎片化,因为即使是针对同样的一类逻辑和数据,不同的应用程序或服务往往会定义不同的数据结构或处理逻辑,这就形成API的碎片化,使得相互之间非常难以协作。试想你可以在两个应用之间协商修改各自的API接口及定义,这是一对一的关系,或者说像支付宝这种平台性质的接口也是容易定义,这是一对多的关系,一对多的关系发展显然是缓慢的,必须让这个“一”有机会且需要时间发展壮大。如果我们希望一种更加高效,更加丰富的协作机制,那么显然我们需要多对多机制,这里面就要求我们对软件开发流程做一些调整。

要想实现这种机制,其实现有的很多技术可以给予很多启示。我们先看USD格式,尽管从表面看USD跟其他的标准类似只是一种数据格式或协议,但实际上它远远不止如此,它还是一种非常易于扩展的格式,它提供了一种plugin的机制使得开发者可以对格式做很多定制和增强功能,并且可以通过一个Schema定义来生成自己定义格式的解析代码,然后通过Plugin来调用自定义的格式解析和代码。这就好比它帮助你编写了文本格式的编解码,尽管看起来不过如此,看起来只是一种模板化的代码生成机制,但是当这种解析代码能够与逻辑高度融为一体的时候,事情的本质发生了一些变化,试想使用USD你的流程是这样:首先针对一种特定数据自定义一个Schema,然后调用USD的API帮助我们生成相关的解析代码,如果这段解析代码能够以某种机制被其他开发者拿到,那么TA的程序就能够轻松解析我们的API。当然如果你修改了Schema,仍然需要对方进行同步,但是这种流程本质上改变了我们的思路:过去我们是先定义内部做法,再与外界沟通,这就容易带来一些复杂度和碎片化;现在是我们先想着自己就是基于一种标准在开发,然后需要的时候就能够很方便地暴露出去,这里USD充当了一种协调的机制并为这种协调的机制提供了一些辅助功能。苹果的usdz格式以及英伟达的MDL都是基于USD的这种扩展能力来实现自定义的资源格式。
API碎片化的第二个例子是LLVM,本质上LLVM在编译器领域的创新主要做的是模块化,早期的编译器开发,各个前端都要分别集成各个后端,编译器开发的复杂度非常高,这里面其实就是多对多的问题,看似很简单,每个前端与每个后端分别调一调,但随之代码的管理和维护成本是很高的,有时候某些内部设计不一致就会导致大量的重复,这就是碎片化问题。由内而外的设计总是不可避免会导致碎片化,碎片化带来软件复杂度,管理和研发成本。当LLVM提供了一个统一的低层IR表述之后,编译器的复杂度大大降低,比如现在能够很轻易地开发一些DSL语言,因为你完全不需要操心后端,只需要把你的代码生成LLVM IR即可。
当然LLVM并没有提供类似USD那种生成格式的机制,那是因为LLVM只有一种IR,所以写成一种固定的格式即可,过去的编译流程基本上都比较简单、固定。但是随着现代深度学习编译器的进展,由于深度学习有着相对比较特定的数据表述,各个公司内部都有开发一些特定的编译流程,它是比一般的LLVM IR更上层的抽象,所以我们对多层级IR表述又有了需求,于是在LLVM的基础上又发展出MLIR,它允许开发者社区能够自定义IR。然而与USD的Schema非常相似的地方是,MLIR为了避免碎片化,使不同开发者自定义的IR之间能够更轻易的协作,它也提供了一种类似的代码生成机制,在MLIR中称为Dialect ,例如如下的Dialect定义:
def Toy_Dialect : Dialect {
let summary = "Toy IR Dialect"; let description = [{
This is a much longer description of the
Toy dialect.
...
}];
// The namespace of our dialect.
let name = "toy";
// The C++ namespace that the dialect class // definition resides in.
let cppNamespace = "toy";
}
生成的C++代码如下:
class ToyDialect : public mlir::Dialect {
public:
ToyDialect(mlir::MLIRContext *context)
: mlir::Dialect("toy", context,
mlir::TypeID::get<ToyDialect>()) {
initialize();
}
static llvm::StringRef getDialectNamespace() {
return "toy";
}
void initialize()
这样多种IR就可以能够被轻易组合使用,你可以选择社区各种丰富的模块进行组合,来生成特定的编译流程,所以MLIR又称作“生成编译器的编译器”。实际上,碎片化在工业界是一个很大的问题,每家公司在开发自己的软件的时候不会考虑那么多,觉得我只要投入研发资源把自己软件做好就行,但是真正在用户侧使用的时候,TA可能需要多个软件是可以相互协作的,甚至你的用户可能就是开发者,这个开发者可能希望不同的软件可以被更高效的集成和管理。LLVM的作者Chris Lattner最新的创业公司Modular实际上核心就是解决这个问题,他的新编程语言Mojo,除了一些语法层面的传统一点的东西,很多核心能力都是来源于底层的MLIR,其中MLIR跟Mojo有更深度的整合,使得Mojo具有很强的元编程能力。Modular的最核心的逻辑其实跟当年的LLVM类似,解决碎片化问题,当然Modular有很多现在软件的运营思路可能会形成更好的平台和生态,因此它是一家商业公司,不仅仅是一个开源项目。
上述的软件架构都为解决应用之间互操作及其碎片化提供了很好的思想,然而为了更好的软件协作,这些机制还不够。上述的软件都是比较偏底层的基础软件,而不是面向上层用户侧的,因此不需要考虑很多其他问题,比如性能和格式的进化。当进入到一个更上层的消费端应用,首先上述的方式在不同的模块之间交换的都是文本数据,如果你让一个实时的游戏内部的每一次互操作都需要编解码文本,这显然是会影响性能的;此外,应用层的需求更容易变化,即使平台提供了一种生成统一格式解析的代码及其发现的机制,但是怎么应对这些格式的更频繁地变化呢?为此,RealityIS在这些方面做出了一些创新尝试。
面向对象编程模型
我们现代的项目开发使用的编程语言,或多或少大部分是和面向对象相关的,尽管看起来面向对象的本质是让我们更好地封装各自比较独立的逻辑,使大规模软件组织起来更加轻松:你不需要关心其他对象的内部逻辑就可以轻易地和它们一起组合起来协作。
然而实际上并不是这样,大部分面向对象编程语言会让人(特别是初学者)误以为编程就应该这样,它是在模拟真实世界的运行机制。那为什么这么完美的模型却没有产生这么完美的体验呢?直到最近一年多对面向对象的更多理解(特别是Erlang)才体会到其中一些问题。
Erlang之父Joe Armstrong在一次采访中(Ralph Johnson, Joe Armstrong on the State of OOP )讲到:
Alan Kay himself wrote this famous thing and said "The notion of object oriented programming is completely misunderstood. It's not about objects and classes, it's all about messages". He wrote that and he said that the initial reaction to object oriented programming was to overemphasize the classes and methods and under emphasize the messages and if we talk much more about messages then it would be a lot nicer. The original Smalltalk was always talking about objects and you sent messages to them and they responded by sending messages back.
Alan Kay认为OOP的核心是关于消息,但是这样说其实我个人觉得并不太好理解到本质,因为消息更像是OOP这种设计下的一种机制或结果,而不是OOP本身的定义。我觉得OOP的本质应该是隔离,只有做到真正的隔离,才能真正降低系统的复杂度,因为绝对的隔离使得你完全不需要也不能了解另一个物体内部的运作,你们只需要通过一些外在的属性进行交互,我们的开发也仅需要了解这些简单的外在属性。现代大部分编程语言更强调的是object和class,认为对象的核心是关于封装,这本身也没有错,封装的目的也一定是为了让别人不需要关注你的内部细节,但问题在于,很多面向对象编程语言忽略了隔离的意义,为了方便程序员更灵活直接地获取数据和方法,提供一些机制,使得一个对象可以很轻易地访问到另一个对象内部的、跟其内部运作相关的数据或方法,这些原本是需要绝对隔离的。这种设计就使得隔离失去了意义,尽管我们可以指定规范要求自己以对象为单位进行绝对隔离,但是大部分情况下,我们很难做到一个很好的设计,最后的结果是程序内部对象之间相互耦合太多,不管是管理、维护、理解起来都是花费很大的精力。
Erlang就采用了一种不同的机制,它从语言体系上就不允许对象之间能够直接访问内部数据或方法,每个函数都分配为独立的线程,线程之间只能通过消息进行传递和联系,这样程序员就很难写出耦合比较深的代码,同时这种隔离对并行计算和分布式也带来了好处。所以Joe Armstrong说,根据Alan Kay的描述,Erlang可能是唯一真正面向对象的编程语言:
Erlang has got all these things. It's got isolation, it's got polymorphism and it's got pure messaging. From that point of view, we might say it's the only object oriented language and perhaps I was a bit premature in saying that object oriented languages are about
再回过来看面向对象的核心为什么是隔离,是因为真正的隔离机制才能保证避免耦合,才能降低软件复杂度,因为一个大型的软件系统有无数的对象,如果对象之间存在耦合的可能,那维护起来将是非常不容易的。而当你只提供了强隔离的机制,不让程序员能够很方便地获取另一个对象的引用,剩下的结果就是对象之间只能通过消息通信了,这就是Erlang的整个架构设计,这也是为什么Erlang是真正的面向对象编程语言。也因此,消息更像是隔离机制带来的结果。
就像现实世界一样,微观的每个原子内部都有自己特定的结构,原子之间相互作用形成分子,进一步形成宏观物体,宏观物体通过内部分子结构形成特定的外在属性,但是其他物体与之交互从来不需要了解其中的内部结构,这就是面向对象的美好世界,然而传统的面向对象编程模式则为了便利为一个对象访问另一个对象的内部结构开了一个口子,这个口子不仅破坏了面向对象的编程思想和精髓,也失去了其带来的好处。
尽管Erlang看起来是一种完美的架构,然而消息通信是一种操作起来不太便利的方式,比如为了进一步解耦它通常是传递字符串消息,字符串需要编解码,带来了性能问题;而另一方面消息编程模型通常是异步的,使得对逻辑的流程管理失去了控制力。RealityIS在这两个方面都做了一些创新尝试,使得开发者既可以像传统的局部变量一样去方面其它对象的数据,又可以像Erlang一样拥有绝对的隔离,这种隔离带来编程复杂度上的减少,降低编程门槛。
虚拟机
基于组合与ECS
例如游戏就是一个这样的例子,尽管仍然有基于传统的面向对象编程模型来开发的游戏程序,但是大部分的游戏框架或架构或多或少都是基于组件的,因为游戏的逻辑非常复杂,没有比较线性的流程,类似于复杂系统,系统跟系统之间存在非常复杂无序的相关性。游戏中的组件某种程度上类似一个Actor,它们都尝试把子系统的逻辑都尽量封装在内部,不同的是,由于组件之间的交互复杂度非常高,例如一个组件的输入消息会来自多个其它组件,而不是像简单的Actor模型只是一对一的通信,因此游戏程序的执行逻辑是按组件进行排序,每个组件有个语义上的顺序,这样的机制保证只要顺序安排得当,就不用去处理复杂的依赖顺序问题,而且当每个组件被执行时,它需要的数据总是能够得到满足。
隔离与沙盒技术
现在整个编程语言以及编译的体系架构,都是基于一个假设,即整个应用程序的所有源代码都被编译为一个单一的应用程序,这也即是编译和构造一个应用程序的主体可以认为是只有一个主体,即开发者,不管你背后是一个大团队或者大公司,最终编译发布应用程序的是一个特定的个人、部门或者组织。这样说有什么意思,这就意味着,整个应用程序的安全性由这个单独的主体负责,你需要解决软件的bug,检查所有可能的安全漏洞等等,保证软件最终运行是可靠的。而对于编程语言来讲,它不对软件的安全做任何假设:理论上,只要你拥有源代码,你就可以几乎访问整个应用程序内存中的数据,所以你必须确保你程序中的所有逻辑行为是正常的。如果所有代码都是由你自己公司的程序员编写的,这当然是天经地义的事情,如果你使用了第三方的开源代码或者闭源的二进制库,你必须由你自己去确保这些第三方的代码不会破坏你的软件运行。
这样天生就将每一个软件当作一个封闭、独立的环境,操作系统的内存分配和管理系统保证你的内存不会被其他进程的程序非法访问,这样软件就可以安全地运行,当然即使如此,你的程序当中涉及对外部数据读取的部分仍然可能导致内存安全问题。然而这种隔离是与我们现实世界的运行方式完全相反的,现实世界整个体系是基于协作和分工来实现文明发展的,计算机本来具有更强大的逻辑体系,然而实际上我们并没有在软件世界建立起比较简单地分工与协作机制。
现代软件变得越来越复杂,这种复杂的体系结构本来就希望能够借助更多的协作与分工的精神和思想来实现更大的复杂度和功能,这种协作的第一个要求是让未受信任的第三方代码可以在你的内存环境中执行代码。这也是《堡垒之夜》面临的第一个问题。按照现代编程语言的一些思路,一个源代码能够在一个内存环境中被执行,那表示其对应的主体知道和负责其中的安全问题,编程语言本身没有太多机制来解决这个问题。这又分为两种情况:静态语言和动态解释性脚本语言。对于动态而言而言,如lua,它们通常不能直接访问内存,开发者所能操作的都是封装在一定类型和对象中,现代大多数编程语言都按照类型进行寻址,也即是类型系统本身基本上可以保证程序的安全,如果你的源代码不知道一个对象的地址,你就不可能访问到它。然而实际现在大多数编程语言都提供静态变量或者全局常量之类的方式,这种方式使得内存环境中的其他代码可以获取到这些共享信息,从而对软件进行破坏。为了避免这种问题,Roblox就对Lua进行了改造,叫做Luau,比如通过禁止全局变量,以及禁止一些能够访问全局变量的库函数等等机制来实现一种沙盒安全,这样第三方开发者开发的代码就可以放心地在Roblox app中运行。
如果第三方未受信任代码是二进制的机器码,这个问题就更严重了,因为机器码是可以访问内存地址和寄存器的,那可以造成的破坏是无法想象的。然而人们仍然希望能够实现类似分工协作的方式,这方面最具有代表性的例子就是浏览器,浏览器是一个非常复杂的软件,现代浏览器往往都可以支持第三方二进制的插件,来提供一些更高性能的增强功能,例如浏览器的字体渲染往往都是使用第三方字体渲染库。为了解决这种由于未受信任二进制代码导致的安全问题,人们提出一些软件隔离(software-based fault isolation,SFI)技术,相对应操作系统或硬件的内存隔离,SFI是用于构建包含未信任组件的安全系统的一种轻量级方法,能够用于减少由于内存安全bug导致的攻击,SFI通过严格将第三方未信任软件限制在自己的沙盒内存区域,来隔离这种内存安全导致的破坏。用例包括浏览器使用SFI来扩展第三方组件,例如经典的Native Client SFI syetem(NaCI)使用SFI来扩展第三方c库,使得浏览器可以使用如第三方的字体,音频,XML解析等库;在边缘计算节点与第三方未信任客户环境进行联合计算等等。
NaCI存在较大的运行时性能,因为它的机制一般对第三方代码不做太多要求,假设其按照一般的方法进行开发,然后仅仅在调用这些方法的时候为其分配独立的内存区域进行隔离,它基本上是用软件模拟操作系统的内存隔离机制,比如每次切换都需要保存大量的状态和寄存器地址等等。为了减少这种隔离导致的代价,Web Assembly就使用另一个思路,由于Web Assembly程序都会编译为Wasm文件,由Wasm虚拟机解释执行,而不是底层的二进制代码,所以Web Assembly有机会对程序进行一定的分析,通过基于Control-Flow Integrity (CFI)技术,Web Assembly的编译器可以检查出程序中哪些代码可能会对这种沙盒环境造成破坏,从而禁止这样的代码生成合法的Wasm程序,因此也就实现了沙盒安全。但是由于这种检查是在编译期,并对第三方程序的构造过程有一定的要求,因此在实际执行的时候就可以避免在这种隔离安全的保护机制上花费过多的开销。
Web Assembly之所以是一种未来非常有潜力的技术,不仅仅得益于对Web的友好,接近机器码的字节码,多语言支持等等,这种沙盒技术也是很大的一个技术点。在Web Assembly之前还没有一种技术可以很好地普及和运用沙盒技术,例如JVM上有一些方案,但大多有些性能问题,或者不能完全保证安全,或者方案比较重。Web Assembly这种优秀的沙盒技术使得沙盒模式在以后的软件构造中可能被大规模使用,也就会实现更多的软件协作与分工,事实上比如现在对未受信任多应用环境要求比较高的环境如区块链就大多转型Web Assembly,而如Docker和Severless这种对虚拟环境要求比较高的环境也在逐步转向Web Assembly。
尽管Web Assembly的隔离技术非常优异,但是它并没有改变程序本身的构造方式,即如果你的代码本身就不含破坏别人的恶意代码,那么其实你的开发过程与过去的方式并没有什么区别。而RealityIS希望简化编程的开发,如本文后面编程方面的内容,我们还希望对编程的体系做出一些调整。因此我们会把各种问题放到一起考虑,而不是单纯一个一个地解决问题。例如软件的可组合性、模块化、编程复杂度的降低、互操作等等。
如后面的内容所知,我们还对应用程序的构造方法进行了调整,而不是仅仅把程序当作一个黑盒子来进行统一的隔离,例如传统的隔离技术大都是基于比较底层的编译惯例,如方法调用(Calling Convention)来设计隔离机制,这样使得不需要对用户的开发过程造成太大的影响。在Reality Create中,我们的每个组件的很多行为和构造过程是由运行时自动推导进行的,因此我们本身已经对用户的开发过程有一定的影响,这同时也意味着我们对程序的结构有着更多信息,因此我们可以在更上层的地方实现一些隔离机制,同时由于上层的机构包含对程序的更多的信息,因此会带来一些新的灵活性和能力。
复杂系统
从两个方面理解,内在结构和外在特征,内在结构通常在工业设计方面有很多实践。外在特征则更偏理论。
A complex system is a system composed of many components which may interact with each other. Examples of complex systems are Earth's global climate, organisms, the human brain, infrastructure such as power grid, transportation or communication systems, complex software and electronic systems, social and economic organizations (like cities), an ecosystem, a living cell, and ultimately the entire universe.
Complex systems are systems whose behavior is intrinsically difficult to model due to the dependencies, competitions, relationships, or other types of interactions between their parts or between a given system and its environment. Systems that are "complex" have distinct properties that arise from these relationships, such as nonlinearity, emergence, spontaneous order, adaptation, and feedback loops, among others. Because such systems appear in a wide variety of fields, the commonalities among them have become the topic of their independent area of research. In many cases, it is useful to represent such a system as a network where the nodes represent the components and links to their interactions.
RealityIS架构哲学
RealityIS的整个架构设计经历了整整一年多的时间,可以参看另一篇文档记录了整个思考过程。整个过程其实是一个非常复杂的思考过程,一开始只有部分残缺的思想,不断在细节和总体之间不断来回切换,慢慢构筑起更完整的体系(我会用一篇博文介绍整个思考的过程)。所以当回来再来看整个架构时,我们必须要形成清晰而简洁的方法论甚至哲学思想。这不仅有助于后来者更好地理解它,而不需要陷入很多细节,同时这也尤其是这样一个面向未来的技术架构具有学习和研究价值的地方。
定义:
RealityIS是一个以互操作性为核心目标的分布式系统和架构,它的愿景是构造一个无边的数字世界,使得任何人都可以向这个系统动态添加新的子程序,这些子程序可以和其它子程序任意交互,这个系统可以像生物系统一样自我进化,从而通过复杂系统的机制涌现出更加智能、丰富和个性化的数字世界体验。
RealityIS通过以下两种理论依据来构筑上述的目标,也即是它的架构哲学:
- 它是区块链去中心化思想的一般化,它将区块链的数字类型延升为通用数据类型,然后通过动态类型系统使得所有虚拟机和程序都可以访问用户任意数据,最后通过数据与功能分离使得这种访问能够被用户授权精确控制。
- 它以复杂系统为理论基础来构筑整个计算框架,用户开发的程序以小粒度的组件为单位,组件之间的交互不需要全局的中央控制,而是通过类型系统实现局部的自动交互,系统内的组件可以任意动态组合。
在上述的哲学思想中,去中心化的思想定义了外在结构,而复杂系统的理论定义了内在结构,我们将在后面的内容中详细分析。
从前面的定义可以看出RealityIS的两个主要目标是:
- 互操作性
- 自我进化
这两个目标的目标则是为了进一步实现更彻底更丰富的数字化,使之真正成为一种人人参与的数字经济。这两个目标也是RealityIS能够区分过去的各种软件或分布式系统,完全的互操作性是数字经济的基础,有了这个基础,更多的数字内容才可以更好地协作,从而产生经济行为。而自我进化则意味着,当我们由现在这种固定功能的软件走向更加动态、丰富的数字世界,这种复杂的交互必须要涌现出新的更高的数字智能,这种智能要超过传统单一软件的功能。
为了实现这两个目标,我们以区块链和复杂系统两个比较完善的理念作为理论基础。尽管区块链并不是专为互操作性而设计的,但从下一节的分析可以看出,我们可以从区块链的一些思想中延升出一种一般化的互操作思想,同时又兼具去中心的能力。而复杂系统的原理和方法论则为这种动态的大规模程序的组织和功能涌现提供了比较稳固的理论指导。
从上面的定义也可以看出另一个重要的方面,即尽管RealityIS涉及软件构造方法,但我们并没有涉及较低层的编译和编程语言层面。当然后面会分析,ReallityIS也绝不单纯是一个软件架构,它也涉及到对编译过程和编程语言一些思想的重新解读,以及将来也涉及对编译器和编程语言的某些改造,但是这种改造主要是结构性的,或者说不会对传统编程语言和编译器的核心部分进行修改。
建立互操作数据抽象
区块链是一个分布式系统,尽管这种系统出现的目标并不是为了解决一般软件开发中的互操作性问题,它也不是为解决传统分布式计算问题而设计的分布式软件架构。但通过洞察它的一些特性,结合互操作性的一些技术需求和特征,我们则可以得到不同的启示。这种启示可以说是RealityIS最核心的部分。
本节我们将从不同的角度来解读区块链系统,以及怎样从这种解读中发现建立互操作系统的方案。
我们可以认为区块链系统有三个技术特征,或者说可以从这三个方面来解读区块链系统:
- 类型
- 数据
- 安全
需要注意的是,这三个层面关注的并不是区块链核心的共识机制的部分,而是它作为一个软件架构的层面。同时这里尽管我们也会涉及去中心化的思想,但是这也并不是指区块链中使用分布式账本存储的去中心化方式,我们考虑的去中心化是指通过一种将软件功能和用户数据隔离的应用程序构建机制,使得应用开发商不再具有掌控用户数据的能力,从而也是一种去中心化的概念。但是这种去中心化依然需要借助某种方式的中心化计算,不过在这种架构下用户对数据具有更透明的控制。
区块链的软件构造视角
如果我们从区块链分布式系统中的任一节点去看,这个节点可以看作一个简单的虚拟机,这个虚拟机每次计算执行一个非常简单的程序,即对某两个账户执行价值交易。我们这里不考虑这个价值交易的算法本身,仅把它当作一个程序,然后思考为了支持这个程序的开发和运行,区块链上的虚拟机应该具备什么功能?
我们知道传统的虚拟机的核心机制实际上就是一个具有某种语法的编程语言的解释器,然后使用这种语法编程的程序源代码作为输入,虚拟机对源代码进行解释并执行,这种编程语言的语法通常支持现代比较高级的一些语法,例如Lua,Python,Java等编程语言都支持这种虚拟机的执行方式。

尽管不是很容易理解,但我们可以把一个程序的结构看成是这样的抽象:即程序由数据、类型和代码组成,如上图(a)所示,当然这里的数据主要是作为程序输入的数据,而不是指代码内部也可以产生的很多的内部数据结构及内存存储,那么这里的类型自然也是指这种外部输入的数据结构的类型。一般的程序,其数据和类型都是定义和存储在程序内部的,用户只是在使用其中的功能。
从这个角度看,我们可以把区块链的账本看成数据,然后账本对应的类型是float类型,对应的代码则是区块链虚拟机执行的共识算法。
但比较隐晦的地方在于,float是一个非常简单的数据类型,并且区块链只处理这种简单的外部输入数据,所以它看起来并不包含一个类型定义。如果我们把这个复杂度延升一下,即如果区块链能处理任意类型的数据,那么就必须要定义类型结构,然后虚拟机以某种方式按照类型定义进行解析。这其实就是传统的虚拟机机制,即输入虚拟机的源代码中包含对于处理的任何数据的类型定义。比如以太坊的智能合约就是比区块链更复杂的脚本语言,它就可以包含更复杂的类型定义。
但是我们这里却不想这么做,因为我们看到了区块链的另一个不同寻常的特性,也就是它的去中心化特性的来源,即它的数据(即账本)存储在一个独立于程序(虚拟机上的共识算法程序)的地方,即数据和程序是解耦的。所以这驱使我们想要进一步弄清楚它的独特的程序组织背后的思想。
如果只是想要单纯地把数据与程序代码分离,直接把数据存储到外部并不是一个好的方法,这里面有几个问题:
- 程序内部仍然会定义解析的数据类型,所以不利于虚拟机扩展处理任意动态的类型
- 存储在外部的数据只是一个单纯的数据,它们并没有多少语义的信息,所以用户既不知道怎么管理它们,也无法理解它们。想想理论上我们任何应用的用户都可以打开存储在应用内部文件夹中Sqlite的数据库,但是哪些数据可能对用户并无太大意义。
用户对数据最通常的管理是授权,保证只有经过用户许可的软件才可以访问这些数据。所以仔细思考区块链系统背后的思想:即区块链可以做到对数据的授权管理,尽管区块链的数据也是存储在独立于程序的地方,但是它可以做到对数据的权限管理,尽管这需要共识机制协作来保证,但从程序的机制来看,我们可以理解为这种使对数据的权限管理变得可能的原因在于:
用户了解数据的意义,然后在交易的时候用户将这个语义传达给虚拟机,虚拟机按照用户指定的意义及权限机制对数据进行处理。这个意义某种程度上就是类型,用户对一个“类型+数据”进行授权,类型在这里升华为某种语义信息或者意义,因为我们在日常生活中所作的事情,其实大多数都是对某类事情进行处理,而这个类型在我们生活中就是包含特定意义的事物,这些事物我们都可以通过名字或类型来区分,类型充当了代表一件事物的语义。
所以当用户在看待自己链上的一个账本数据时,这个数据不光只是一个数值,同时也代表了账本这个类型,只不过由于区块链的虚拟机仅处理这一种数据类型,所以这个类型被隐式表述了,即使没有任何地方定义这个类型,区块链虚拟机也总是能够正确解析这个数据。并且当用户通过给出密钥进行授权计算的时候,TA表达的就是对账本这个类型的数据进行授权。
所以要想把区块链上述这种程序视角的意义扩展到一般程序,即让任何程序的数据都可以独立于程序的代码而存储,并且用户可以对数据进行授权管理,那么我们可以从一下三个方面对区块链进行扩展:
- 将单一的float类型扩展为一套动态类型系统
- 将数据按类型存储在独立于程序代码的地方
- 虚拟机在运行时配合用户的权限设置对数据进行访问
一下我们分别深入分析这三个方面的扩展涉及到的一些思考和逻辑。
类型
程序要对数据进行处理,当然必须要知道正确的数据类型,即知道数据内部的每个字节表示什么含义。通常外部传入一个json字符串,然后程序内部首先会定义一个对应的数据结构类型,然后有一个解析函数对json字符串进行解析并将之转化为内部数据结构的一个对象。如下图(a)所示:

但如前面的分析所知,这里会带来两个问题:
- 用户数据管理和授权的问题
- 程序根据用户授权进行安全控制
由于解析器在程序内部,所以数据对于用户而言仅仅是一些字节,如果有非常多的数据,用户根本不知道哪些数据是对应什么意义,即使用户可以自己去根据文本内容自行判断,甚至给这些文本数据加上一些标签或名字,但是这不仅会增强用户对数据的管理复杂度,而且这种分类行为或结果与实际的数据意义可能还是不一致的。因此,用户无法针对数据进行授权管理。
对于第二个问题,由于解析器处于程序内部,那么就无法保证程序会遵照用户的授权结果进行处理。首先同样因为上面无法对数据进行授权的原因,也不存在一个外部程序可以确保数据会按照用户的旨意被某个程序处理,因为谁都不知道这个数据的意义的什么,这种情况下只有将数据传递到程序内部,由程序内部的解析器去做类型解析和分析才知道数据的意义,也就是说只有程序才知道数据的意义,但是这个时候数据已经被传递给程序了。因此,系统也无法根据用户的授权旨意将数据分配给合法的程序。
上述的分析要求,数据的形式及其定义应该在一起被管理,也就类型的定义应该处于程序之外,这样不仅用户能够知道数据的意义,从而能够正确地做出权限控制,而且系统可以借助类型系统以及用户的授权组织数据被传入未经授权的程序。即如上图(b)中所示。这就要求类型系统是独立于程序的。
这是一种非常有启发意义的视角,我们单纯去看区块链系统,很难得出这样的思维,但是其实仔细分析也是合理的。我们可以认为区块链其实包含了一个公共的类型系统,只不过这个类型系统只是包含数值类型,也至于我们甚至不需要去定义这个类型系统,这样导致人们对它的类型系统可能没有感知;然后区块链类型系统的解析器是位于虚拟机上的,即由系统控制,系统在对数据按照用户的授权执行权限控制,最后获得授权的请求才会执行最终的交易计算,我们可以认为交易才是真正的客户程序,而交易之前的类型系统和授权计算是属于平台虚拟机部分,这部分客户程序是无法控制的。

最终我们看整个类型系统的架构,它类似于上图所示,这里客户程序(program)仅仅是包含代码,数据被存储在其它地方,用户可以离线对数据进行授权,指定哪些程序可以访问哪些类型的数据。然后运行时这些数据被首先加载的虚拟机VM,虚拟机首先根据类型信息对数据的权限进行判断,如果这个程序被授权,则调用解析器帮助程序解析格式,并最终将程序放入到某个约定的内存地址,最后程序从这个内存地址取值进行计算。
当然实际整个类型系统的工作机制还涉及很多内容,我们在后面架构设计一节将详细介绍。
数据
区块链的另一个特点是数据的存储是未受保护的,甚至是明文的,任何程序都可以获取用户的账本信息。这跟传统的应用程序架构思想也是截然不同的,传统的应用架构就是为了保护用户数据而将数据完全隔离,甚至加密以防止其它程序触碰到数据,但是它们通常在内部则不做太多安全检查,假设对数据的访问都是合法的;而区块链的哲学却不一样,它认为数据的存储不重要,重要的是数据的所有权,所以它的核心是在运行时做授权检查。当然这里只是一种架构上的类比,区块链公开明文数据的机制也是由于其核心的共识机制决定的。

如上图(a)所示,传统的程序将数据隔离起来,以防止其它程序访问,这种隔离机制往往是在编程模型之外的机制,由操系统来提供,因此程序不需要担心数据的安全性。例如常见至少有三种数据保护机制:
- 文件系统和应用程序沙盒环境,在现代移动操作系统中,每个应用往往都分配有独立的数据存储空间,应用程序可以将其运行过程中产生的数据存放至这里。像iOS操作系统则会为这个程序的空间创造一个沙盒环境,使得只有所属的应用程序才能访问这个环境中的一切数据。
- 操作系统内存隔离,当一个应用程序启动后,尽管理论上所有的应用程序都是共享计算机硬件的内存,但是现代操作系统及硬件提供了很多隔离机制,使得每个程序被分配一块内存的区域,并且不管其程序代码中访问的内存地址指向何处,都不可能访问到程序之外的隔离区域。我们将在后面讨论这些机制。
- 虚拟机沙盒环境,像Java、Web Assembly、.NET CLR等现代虚拟机环境,它们往往提供一种多种编程语言的程序互操作的能力,尽管保护力度和性能不一样,它们还或多或少提供了一些在同一个应用内部隔离不同子程序的能力。这种情况下,因为整个虚拟机及运行在其上面的所有的程序都是在一个内存环境中,所以操作系统的内存隔离无法提供保护,虚拟机往往需要模拟操作系统的某些机制来实现应用内的内存隔离。这种情况下,对于虚拟机上的每个子程序来讲,虚拟机环境本身有点类似于操作系统的概念了。
从上面的分析可以看出,过去几十年计算机软件构造的发展历史,逐渐形成这种操作系统与编程模型的分工协作,也是一种硬件上的抽象,在这种抽象模型中,硬件或操作系统只需要提供如文件或内存级别的安全访问机制,而不需要关注应用实际的数据和数据结构,就可以保证数据安全;而对于应用程序,由于硬件或操作系统已经保证了数据不会被其它程序非法访问,那么整个编程模型涉及的机制只需要考虑应用业务逻辑的构造,而不需要考虑数据的访问安全,并且现代编程模型基本上都基于一个假设:即代码可以访问该应用程序内的任何资源,只要它能获取到相应的内存地址,例如在C++代码中,一个指针可以指向和访问任意应用程序内部的内存地址,即使是那些不能使用指针的脚本编程语言,它们的核心也主要是在帮助简化内存管理,而不是阻止对应用程序内任意数据的访问,例如一个对象的引用你可以传递给任何变量从而被使用。
过去几十年,这一套机制运转良好,也体现出这种抽象带来的高效率。但是这种抽象只考虑一个程序及其程序的执行,而没有考虑程序内部数据对于用户的意义。在传统的软件中,软件主要是作为一种单一的功能使用,这种功能很少涉及需要跟外部交互,它们整体在内部是自洽的,如果用户需要另一个功能,TA就去打开使用另一个软件就好。
然而近几年随着Web 3.0、元宇宙和多智能体类应用的出现,这些应用越来越凸显出相互交互和协作的特性和需求,这跟我们传统的应用构成模型是相悖的,数据隔离就失去了互操作性,尽管我们可以通过一些机制去提供一些接口让其它应用进行互操作,但是这些机制架构通常都很复杂、不可扩展、效率低下。
因此,或许我们应该像区块链系统一样,建立一层数据抽象。它可以带来天生的互操作性,同时后面我们将看到,这样的架构调整还可以带来很多新的计算特性。但是首先来看将数据与应用程序分离之后怎样保证数据的安全。
安全
将数据存储在应用程序之外的地方,就失去了硬件和操作系统的保护,那么平台或者应用程序就必须额外提供保护机制。这方面我们也可以从区块链系统得到一些启示,再结合传统软件架构技术的一些发展,找到一个合适的技术方向。
不考虑分布式环境,仅考虑单个虚拟机,我们可以认为区块链计算的过程如下:首先虚拟机从外部环境中获取到用户账本,然后基于用户授权执行验证计算,验证通过则执行具体的交易,我们可以把这三部分分别看作数据、虚拟机和应用程序,如下图(b)所示:
首先数据存储在应用程序的外部,从前面数据部分的分析也可以看出,所以在程序运行的时候就涉及到一个数据的传输过程。关于网络传输的安全性,我们已经有了很多年的软件工程实践,这块并不会带来很大的问题。而实际上,比如在移动端这种情况下,用户的数据大部分是存储在本地的,这并不需要经过网络传输,实际上整个系统只有需要与其它用户进行交互的数据才会进行网络传输。
当数据到达本地虚拟机时,虚拟机首先执行权限计算,然后再决定一个应用程序是否可以获取这个数据以执行某种计算。这里由于虚拟机已知用户的数据类型,所以它能够对数据进行授权管理,用户可以很简单地对每种语义数据对每个应用程序进行授权,只有相应类型被授权的应用才可以访问到对应类型的数据。所以这里虚拟机完全可以执行整个授权计算。
随后,被授权的应用最终可以获取到数据执行某个逻辑计算。尽管数据需要执行权限计算,但是应用程序对这种计算并无感知,它还是像传统应用程序一样进行开发,例如它声明需要访问某个数据,如果这个数据没有被授权,它根本就不会被调用执行;如果数据被合法授权,则它的计算过程跟传统的计算是一样的。整个授权的行为对应用程序是透明的。
这种数据及其安全的抽象,使得应用程序的开发还是利用完整的传统应用开发流程,保证对开发者流程和习惯的影响带来新的学习成本和思维模式转变。而这里的虚拟机则仅有平台进行开发即可。
对于虚拟机的安全部分,传统的一些虚拟机技术如Java、Web Assembly等已经有了很多的实践可以借鉴。本文后面也会提出一些新的调整思路,以解决一些新的问题和新的思考。
数据抽象带来互操作性
Reality World显然不是一个区块链的架构,比如我们每个应用的主体逻辑计算主要还是在单机上计算,就像传统的应用程序一样,但是它从区块链背后的技术体系中提取中了一种很有价值的思想。这种思想来源于区块链核心的共识机制,即它需要在一个分布式系统中的所有虚拟机上执行相同的计算来达成共识,这就要求虚拟机上每次计算的输入数据,即执行交易的两个用户的账本数据,首先必须对每个虚拟机是公开的,这样它们才能顺利地获取到数据,也即是可以互操作。这是一个非常智慧和巧妙的思想,任何尝试像传统软件架构那样把数据放在一个受保护的地方,然后通过定义API等等方式提供访问都会带来巨大的软件架构上的复杂性,比如你的编解码方式、传输内容的格式都需要两边进行很多配合,带来很多的碎片化。同时,数据的解码一定不能在客户应用程序内发生,这样客户程序就始终会拿到数据,进行不可能预期的操作,解码操作必须发生在平台。如果解码操作发生在平台,我们就不需要设置复杂的数据保护措施,因为这些数据的存储以及解码的过程,启示就发生在平台内部,对客户应用程序是不可见的。
数据可能不重要,所有权才是最重要的,这是区块链思想对于传统应用架构的不同视角,它带来了新的应用形态和体验,与之同时也带来了新的软件架构思想。
尽管区块链并没有很强调互操作性,因为它的格式和系统足够简单,但我们尝试把这种思想往通用计算上去思考的时候,它就会演变成互操作性的概念,想想你在区块链的虚拟机上怎样解析用户的另一个非账本的复杂数据结构?
这种从互操作性的角度去思考区块链,以及从中得到对软件架构的启示,它为未来的数字世界软件架构带来了全新的世界和可能性。它甚至打破了传统软件架构几十年发展的思维,未来的数字世界会因为互操作性呈现完全不能的能力和形态。从后面的内容会无处不在地看到这种互操作性带来的各种新的可能性。
更重要的是,我认为这是未来实现更加智能数字世界的基础,即数字进化。
基于复杂系统的计算架构
前面我们讨论了在一个多应用程序环境中,应用程序之间的互操作思想和机制,即系统架构的外在结构。本节我们关注的内容是系统内部逻辑的组织方式,即内在结构。
我们关注两个视角,这两个视角都来源于复杂系统理论:
- 首先是大规模复杂系统内部的交互和逻辑组织问题
- 其次是怎样通过复杂系统的涌现机制产生更加智能的数字世界
这两个视角将会让我们重新去审视过去几十年来形成的软件架构及其编程模型的思想,我们将通过把复杂系统的一些理论和思想引入到软件架构中,从而形成一套开发具有复杂交互的软件架构方法和逻辑,更重要的是,这种新的视角可能有助于未来我们开发出更智能、更丰富的、更复杂的数字世界体验。
游戏的复杂系统视角
上一节我们分析了,现代软件开发的其中一个基本的假设是程序所有的数据和代码都是受程序开发者控制的,这带来了中心化的软件治理模式,进而形成中心化的数字生态。中心化有效率的优势,去中心化有数据安全的优势,我们则从两者中做出一些架构调整形成一套集两种优势的架构。
本节我们将分析传统软件架构的另一个机制的缺陷及其带来的影响。
在现代的编程模型中,不管编程语言本身对硬件的抽象度如何,整个程序最后要被硬件执行,都会被编译或解释成这样一个机器码或字节码的字符指令集合,这些指令一般由操作符和操作数组成,操作符是其计算平台支持的计算类型,而操作数大部分是涉及到硬件的地址的,一个程序通常包含三类地址:
- 寄存器
- 内存地址
- 程序机器码中的代码地址
这其中寄存器地址大部分是由编译器来分配的,而内存地址和代码地址则是和程序的结构有一定的关系。其中内存地址通常是我们程序在运行过程中创建的数据对象在内存中的地址,然后其它一些需要访问这个对象的指令通常就需要指向这些对象的地址;而代码地址则通常跟方法调用有关,我们编写的代码最后会被编译为一个机器码格式的数据表述,程序运行启动时则会首先将这些代码数据加载到一片固定的内存地址,后续所有代码的执行实际上都是需要首先从这里获取代码指令的数据,然后根据指令的定义执行计算,然而实际代码的执行并不是完全按顺序执行的,我们的逻辑中充满很多控制流,例如一个函数需要调用另一个函数,这个时候就需要首先将指令的指针指向另一个函数的地址,并在指向完毕之后跳转回原来的位置。所以我们的程序代码中还需要根据逻辑控制流将这种代码地址编码在指令的操作数中。我们将在后续的技术架构部分更详细的讨论这个过程。
尽管上述的过程一般主要是由编译器、链接器和加载器来协同完成,但是从本质上来说,一句代码要访问那个对象的内存地址,以及下一个语句要跳转到哪一条语句,这其实是应用的逻辑规则,因此这些逻辑定义是由程序员来定义的,编译器只不过是根据编程语言的语法描述,将这种程序员在编程语言级别的定义,转化为机器级别的定义。
按照传统的软件架构方法实践,这里就会出现两种问题:
- 一旦某句代码访问指向了某个对象地址,这个行为就不容易修改
- 一旦某个跳转语句指向了某个函数的地址,这个逻辑流程就不容易调整
尽管我们有很多软件架构实践来部分缓解上述两种情况带来的问题,但通常都没有理想的方案。这造成的一个主要结果就是,我们的程序一旦开发编译完成,其行为就不容易动态调整或修改,一旦进行修改,则需要重新进行编译发布,并要求用户重新更新整个程序。
上述技术层面的因素反映到用户体验或者软件形态层面,就是当前的软件形态大部分都是一种固定的形态,每个软件的功能和结构基本上都是固定的。与软件的数据和代码耦合在一起导致软件失去互操作性类似,软件中数据的地址与软件结构的耦合使软件失去了动态性。关于软件的动态性有两个方面的意义,下一节我们回讨论动态性对于智能进化的意义,本节我们先讨论动态性对于软件逻辑构造的意义。
复杂系统结构
如果一个软件的业务逻辑是相对比较确定且简单的,那么我们传统的软件开发模式是可以很好地工作的,比如看看我们现在手机上大部分应用,每个应用内部的功能相对还是比较简单的,尽管有比如高并发等类的软件架构问题,但这类问题跟复杂度本身没有太大关系,更多是技术架构的问题。这类应用的特征是其业务逻辑的复杂度基本在人脑能够理解的复杂度范围之类,内部开发人员通常不需要太复杂的推理和思考就能够理解软件内部业务的流程、逻辑等等。
我们看另一个类型的应用:即游戏,则不一样。我们在后面还会分析很多游戏架构的特征,但是这里先重点关注其中一个特征,即它的业务逻辑的复杂度。总体上它的复杂度相较于传统的应用有两个特点:
- 它由非常多的逻辑关系没有那么清晰的子系统组成
- 这些子系统之间的交互呈现高度的动态性和局部性
在这种情况下,我们几乎很难像传统的软件那样进行编程,它没有比较明确固定的逻辑说什么流程之后就会执行另外一个流程,它更多是根据很多来源不同的条件来决定执行什么流程;它也不能将指针指向某些固定的内存地址,它有很多不同不同的对象实例需要执行相同的逻辑。总之这种软件的复杂度是非常高的,我们通常无法很直观地用大脑去思考它内部的交互逻辑。
具有这样特征的系统通常称为复杂系统,实际上关于游戏设计的理论,大部分都是基于复杂系统的思维来思考的。前面我们已经介绍过复杂系统相关的基本概念,我们可以从两个维度去理解它:
- 内在结构,内在结构通常侧重在描述构建一个复杂系统的架构思维,比如它们的子系统的交互机制是怎样,整个系统是怎么组织的。
- 外在特征,外在特征更关注的是观察一个复杂系统,它会呈现出什么特征,这方面通常是设计复杂系统的理论,因为一般的复杂系统理论更偏重寻找复杂系统的原理而不是关注它内部的结构。
我们也从这两个方面来思考软件架构,首先讨论它的内在结构,后面再讨论它的外在特征。
游戏中的组合架构
为了解决程序逻辑中的动态性的问题,一般的游戏应用架构都选择使用非常不同于传统软件开发的架构,这些架构大部分都涉及用某种形式的组合来代替继承。这其中不光是由于继承带来的逻辑表达的复杂性,使用组合还可以更灵活地调整程序的结构和功能。
最简单的组合机制如下图(a)所示,对象A并不是由某个具体的类通过继承等方式来继承,而是通过把不同的组件组织在一起通过组合的形式来构建。这种组合方式通常不是编程语言的机制,而是使用类似一个配置表格来记录这种组合关系,然后程序运行的时候根据这个配置分配相应的组件对象地址,并在组合的对象中以某种形式记录这些地址,以方便可以快速地访问这些组件对象。

组件对象本身的定义没有太多限定,一般简单的方式是每个组件包括自己的属性、状态和代码,另外一些更好的架构比如ECS则是将组件的数据和功能分开,这样方便组件之间的数据互操作。但不管怎样,对象内部的组件之间是需要通信的,对象和对象之间的某些组件或者属性之间也是需要通信的。如上图(b)所示。
一般简单常用的方法就是设置可以能够被全部对象访问的Manager类,这个类能够根据类型或者名字查询到其它组件或者对象的实例变量,例如伪代码:
manager.getChild("A");
manager.getComponent<Attack>();
这样的方式很灵活,它避免在我们的代码中到处去寻找每个对象或组件实例的位置和地址,简化为通过对象名称或者类型信息来获取对象。但是它的缺点是我们暴露了一个权限很高的访问入口给每个对象或组件,尽管对于游戏开发商内部来讲这没有问题,但是如果我们希望游戏程序能够提供给玩家一些自定义的选项,在这种情况下,玩家可以自行向程序注入一些动态的脚本程序来实现不同的玩法和目的,这种架构却是不可行的,而这也是元宇宙所描述的世界尝试构建的架构。
去中心化的交互控制
构建开放的程序架构不光涉及对其它资源的访问权限控制问题,还涉及到去中心化的子程序交互控制问题。
这是什么意思,由于系统的功能和状态都是完全动态的,因此我们无法预测一个组件执行时它需要的条件是否完全满足,在上述伪代码示例中,组件获取到的对象可能是不存在的,当然我们可以在每个组件内部做是否为空的判断,但是我们有没有一些更好的架构方法呢?
近几年改进出来的ECS架构可以找到一些启示。在例如Unity DOTS或Bevy ECS架构中,在这些ECS架构,组件的数据和功能被分离开来,分别对应Component和System,每个System对数据的使用,由上面那种自己需要通过全局共享的manager变量去查询获取,改变为通过一个query参数来声明对数据的需求,例如如下的System声明它需要使用Transform数据:
fn print_position_system(query: Query<&Transform>) {
for transform in &query {
println!("position: {:?}", transform.translation);
}
}
这种Query形式的声明,借助Rust编译器对宏的一些强大支持,使得我们不需要写一些额外的查询语句,基于类型就可以获取到正确的对象变量,这种方式甚至比函数调用还要简单:都不需要我们手动传递函数参数,只需要声明类型就可以在运行时被自动赋予正确的函数变量。当然Unity使用的C#语言编译器的机制没有那么强大,但对应的思路是差不多的。
这种机制带来的意义是非常深远的,它不光简化了传统编程开发中,一个逻辑在执行时需要收集大量复杂上下文数据的流程,更深远的意义在于,通过分离数据的声明和数据的实际获取的过程,将数据的获取过程转交给系统,使得系统有机会去控制组件对数据获取的安全控制,同时又不会给客户程序的开发带来复杂度,甚至还大大简化了。
结合我们前面的区块链的思路,由于我们的数据的获取是没有做保护的,但是我们在这个数据获取到组件的使用之间,虚拟机会根据组件的类型声明执行安全检查,此时我们知道组件声明的类型,这个类型是虚拟机可以解析的,我们也已知道用户对于该组件对于该数据的授权情况,我们完全就可以在虚拟机层面非常简单地做出安全判定,如果我们还能够根据判定结果来执行函数功能,那么非法的组件完全就没有可能被执行,即使它看起来可以声明获取用户的任意数据,所有的数据所有权都在用户的精确控制之下。
这种机制也为我们带来去中心化的交互控制便利。由于复杂系统的子系统非常多,且整个系统是高度动态的:随时可以有任意的子系统因为某些原因被停止执行,也随时可能新增某些新功能的子系统,所以我们很难用全局的控制器去管理这些动态的组件之间的交互,实际上所有复杂系统的核心就是整个复杂系统没有中央的控制机制,所有子系统之间都是局部的交互,整体涌现出智能行为。
如果组件只是声明交互关系,没有与某个中央控制器或者全局的共享变量交互的机会,系统或平台就有机会根据类型等信息进行动态判断和规划,使得不满足条件的组件根本就不会被执行。这样在每个子系统看起来,整个系统并没有一个中央控制器,能够最大限度支持复杂系统的动态性。
这种简单对类型的声明,然后由系统来分配数据的架构,也支撑了我们最核心的互操作性特性。
动态性
游戏程序或者说一般的复杂系统,相对于传统的应用架构还有另一个特征,那就是信息是完全动态的。
在传统的应用中,软件主要充当的是一个功能计算器,它的功能大多数时候都是静止状态的,只有当用户发起某个事件,例如点通过鼠标或触摸屏点击某个UI元素,这个UI元素被程序定义为绑定到某个功能,一旦用户发出输入事件,对应的功能计算就会执行,然后程序会呈现相应的计算结果给用户。此后程序又进入静止状态直到用户的下次输入。这种模式可以描述为:输入-->计算-->输出,如下图(1)所示。

而游戏并不简单的这种模式,游戏世界的一切都是动态的,它背后有一个循环驱动着整个系统持续在运行,即使用户不做任何输入,它的状态也在时时刻刻发生变化,例如大部分游戏的关卡都有时间限制,即使玩家什么也不做,游戏也会以失败结束;例如在一个RPG游戏中,即使玩家站着不动,周围的怪物也有可能走过来攻击玩家,导致一连串的后果。
游戏程序就像内部有一个驱动器,它持续驱动着所有系统的运行,这些系统与系统之间的交互会导致很多状态变化,这些变化的状态信息源源不断地输入给玩家,如上图(b)所示。
这种行为也是更接近真实世界行为的,在真实世界中,不管是生物系统还是人工影响的如经济系统等,环境时时刻刻在发生变化,整个世界的信息绝不仅仅是我们自己去影响的,事实上更是反过来我们的行为都是受环境的信息影响的,我们所作的任何决策都要实时去观察环境的信息,有些上一刻看起来还理所当然的决策,在下一刻随着某些环境发生变化就变得毫无意义。
这样的信息系统特征与我们的传统应用程序相比,表现出两个在计算上完全不一样的特征,即:
- 系统之间的交互是完全被动式的
- 软件给用户呈现的是一个动态的信息世界
被动式计算架构
当一个信息系统的交互控制是去中心化的时候,子系统之间的交互看起来都是“自发的”,没有谁来驱动,这样的机制怎么执行的,我们将在后面讨论整个复杂系统的机制,这里我们先来看看这种行为对编程有什么影响。
传统的编程模式都可以称作为主动式,大部分的代码流程可以总结为:用户输入-》决策判断-》执行动作,这里的决策判断是程序中最复杂的部分,因为它涉及到很多上下文信息的组织和查询,关于上下文的理解知乎有一篇很精彩的描述。在传统的软件架构中,我们一般都会有很多不同的模式和经验来实现这种上下文管理,但是这里我们在复杂系统的视角下,却会提出另一种可能是更好的方法。
一般的决策判断流程大概是这样,当对应的代码接收到用户输入请求的时候,决策代码要做的事情就是去查询和收集上面讲到的这种上下文信息,以帮助做出决策判断,不考虑这些上下文内部是怎么组织的,我们可以把整个根据上下文进行决策判断的过程看做一个函数makingDecision(),makingDecision要做的事情就是去调用大量预置的判断函数,根据各种逻辑条件,动态地计算出一个判断结果。这种计算架构带来了两种不好的结果:
- 造成了模块之间的耦合,即所有子模块都需要引用或者了解哪些逻辑判断的代码
- 造成逻辑判断计算的重复执行,设想有两个独立的用户输入,其中的逻辑判断有80%是重合的,程序必须针对两个独立的输入进行这部分重复计算。
看看我们现实世界的系统往往不是这么工作的,各种系统往往定义好自己的流程,每个流程会输入数据,后续流程往往以这种输出的实物数据作为它可以执行流程的判断条件,而不是当它需要执行的时候,发现前面的流程还没有执行,由下游的流程再去驱动上游的流程去执行。在这样的模式种,上游流程计算的数据结果不仅充当了一个条件,它更充当了上游的那个计算过程。
结合我们前面的互操作能力,即子系统在不经过某个中央控制模块的情况下,能够非常简单地访问所有数据的能力,我们可以把各种可能的决策计算提前计算为一个数据,这样下游的流程由于定义和数据依赖关系,系统可以在条件满足的时候自动调用它去执行自己的逻辑。整个过程中,决策判断和子系统完全解耦。
这样的架构调整将传统软件种的模式由主动式转变为被动式。
动态的信息世界
传统的:输入-》计算-》反馈的计算模式,用户能够完全了解或者说“记住”一个软件的状体,用户知道自己做过什么,当前的软件状态是什么,用户也知道TA只要执行某个功能,就会带来什么可预期的结果。
尽管这样的方式有助于人们管理日常的任务和工作,但是这既不是真实世界的工作方式,同时所有事情都靠人去输入驱动,那么信息系统所能完成的事情的数量就会非常少,因为人的精力和注意力都是非常宝贵和有限的资源。而现实世界的信息系统总是在自发、动态发展的,即使我们某天什么事情也没有做,但是世界发生了很多的经济和生产行为,所以我们应该模拟真实世界的动态行为,使得数字世界的计算不以人的注意力为驱动基础,这样即使当我们的注意力不在软件和应用上,但是它们会在后天时时刻刻都进行着与用户相关或者指定的计算任务。
前面我们已经描述了实现这样的计算架构的机制,这里要强调的是这对用户体验带来的变化。传统的软件的信息状态都是跟用户的输入有关,因此即使不用打开软件,用户大致是知道里面的状态信息的。但是如果一个信息系统在后台动态运行,就会存在大量的信息状态是用户不知道的,它必须像观察这个动态的世界一样去观察软件内部的信息状态,当然这里的交互可以有很多形式。
游戏就是这样一个信息系统,游戏内部有许多子系统的运行都不是直接与用户的输入相关的,因此游戏的交互必须要很好地呈现比较完整的状态信息,比如相对于传统应用简洁的界面,游戏的界面通常会包含很多全局的数据信息,除了具体的数据信息,游戏场景的元素在视觉上通常也被设计为易于帮助用户去区分不同的场景状态,如下图《文明》这款游戏一个游戏画面。
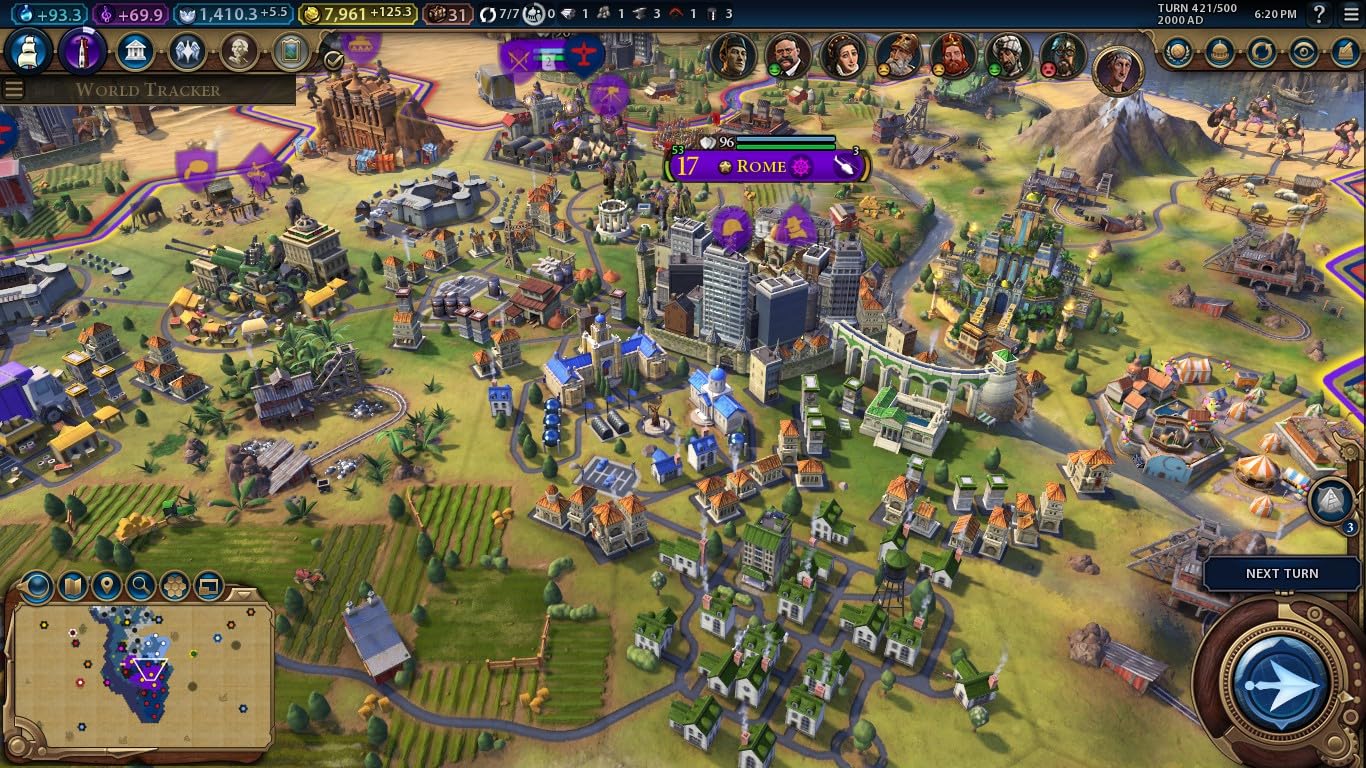
在这种情况下,用户的下一个输入或者决策,就不能单纯凭借自己大脑种的记忆,而是需要观察整个系统的信息状态,这些状态可能会实时变化,甚至大部分变化都不是用户直接输入导致的结果,甚至某种程度上用户的操作更多是在响应信息世界的状态变化。
表面上这看起来是更复杂的,但是这样的信息系统能够处理的信息计算将会远远超过传统的信息计算,因此它能实现的信息计算的复杂度也更高,想想看一个游戏中涉及的那么多计算和逻辑,使用传统的应用模式几乎是无法实现的。
而且这种复杂度对于人类来讲,或许并没有那么复杂,人类在社会中天生就是被训练为适应变化的环境的,我们不断在观察街上的行人、红路灯及车辆情况,以决定下一步的行动策略;赛场上球员之间不断观察其它运行员动态的情况,以决定下一步行动;甚至在信息系统中,我们也要根据股票市场的变化,决定下一部分的投资决策等等。
所以这里更多的是设计和交互的问题,比如人的有些响应能力是天生的,比如对危险事物的察觉,有些则是需要定义一定的规则然后进行适当的训练的,比如开车时对环境的反映等等。这比如就要求我们要精心选择呈现信息的逻辑、模式、规则,而不是一股脑甚至随机选择大量杂乱无章的信息;比如一段时间内某些相关信息的规则和逻辑变化不能太大,因为这可能需要用户重新去建立对动态信息的响应模式。
在这种信息系统中,信息的呈现、规则和交互会变得很重要,但是相比于这样的复杂信息系统呈现的价值:注意力的释放以及实现更复杂计算的能力,以及人类对这种动态信息系统的适应能力,这样的转变完全是有价值的。
进化产生数字智能
前面我们从机制上讨论了很多思路,以实现一个可以多子系统互操作、靠子系统局部交互实现更复杂功能的数字世界。但我们花费了这么大的精力去重构软件开发的流程,以及让用户去学习新的信息系统交互方式,这样的代价到底值不值得?它有没有更深层次的价值体系来支撑这种技术变革?这些是本节要讨论的问题。
本节我们要讨论两个很深刻的问题,即数字智能和计算的本质,这些概念可能性驱动未来数字变革的核心价值。
智能涌现
前面我们已经简单介绍过复杂系统的一些基本知识,我们再来看一个每个人可能深有体会的例子。
考虑我们现在的整个网上消费购物的系统,它是由这样几个子系统构成的复杂系统,包括生产产品的厂商、物流快递、国家交通公共基础设施、电商网站、送货的快递员和用户等。这些子系统每一个单独看都比较简单,它们的功能有自己的边界,这些子系统之间的交互也相对比较简单,最重要的是,这一切没有一个公共、统一的中央控制器,整个系统都是由局部的子系统之间进行简单的相互交互,从而呈现整体系统功能的。
虽然每个子系统相对都比较简单且容易理解,但是整个系统实际表现出来的功能性是远远大于我们的预期的,例如最开始网上购物主要是以淘宝等少数电商网站为主,然后现在快递称为一种公共子系统,使得任意其它的电商网站都可以接入,这就使得人们购买物品这个体验大大升级,例如小到附近的餐厅、水果店和药店等都可以很方便的购买,甚至包括跑腿这种灵活的形式,从我们的体验上说这已经不单单是一个快递或者购物网站那么简单,它简直是一套非常智能的消费体系,因为几乎所有的电子消费形式它都可以实现,这种智能就是通过这些子系统构成的复杂系统涌现出来的。
除此之外,由于这些子系统之间的形式是相对比较独立的,所以子系统都在进行自我迭代,例如过去的物流体系主要是依赖火车,其运载的时效性是非常低的,随着现在交通子系统内部的迭代,例如火车升级为高铁和动车,大规模高速公路网的修建,其它的子系统甚至在没有变化的情况下就能享受到交通子系统的性能提升,最后导致整个消费的体验大幅提升。再比如说快递这个子系统,过去快递可能就是送到站需要用户自取,但是随着消费量的增加,快递公司为了改善体验,逐步增加了配送到家里的最后一公里,甚至在大城市通过分片区配备更多的快递员来缩短配送时间。所有这一切,每个子系统内部都在迭代和进化,最后整个系统的性能和能力都不断突破,子系统内部逐步的迭代改善不单单是提升了性能,它使得整个系统涌现出一些新的体验和能力。例如快递员的配送时间不能控制在很短的时间内,那么这种短时的外卖消费形式就不可能形成。
从这里我们就可以看到复杂系统的力量,它通过将整个系统划分为自治的子系统,并允许子系统内部进行进化迭代,从而涌现出更智能的功能。我们可以从人类社会的各个层面都看到这种复杂系统机制涌现智能的例子,从生物系统、到人造的各种系统,如上面描述的这种电子购物的系统,再到天气宇宙这种大自然的复杂系统。
尽管信息化以及计算机的通用计算能力具备表达和模拟人类一切可计算的逻辑的能力。然而在数字世界我们似乎还没有感受到这种由复杂系统机制导致的计算智能的能力,这主要是因为前面论述的现代软件构造的基础架构使得应用之间的互操作性很低,从而不利于实现相互交互来形成复杂系统。比如看看我们手机上的应用,几乎每个应用之间都是完全隔离的,尽管理论上用户的数据本身应该在不同应用之间可以共享,但是实际上一个应用很难使用或获取另一个应用产生的数据。这造成的结果就是,虽然现在的应用商店有成千上万的应用,每个用户也下载了非常多在功能和意义上具有相关性的应用,但是这些应用之间从不能真正进行交互,使得这种“多应用”的形态最终没有涌现出更复杂、更丰富、更智能的数字体验。每个应用本身就像一个完全独立的小功能,甚至应用之间由于数据格式的不同,即使是用户想要手动在应用之间形成这种协作,也无法操作,当然除了简单的图片、视频、文字等这几种标准的格式之间可以手动实现交互,其它更多的数据是没有通用格式的。
说明:这里并不是说数字世界完全没有复杂系统产生,但这里本文说的主要是面向C端消费者的应用之间。其它的不同层度的互操作还是有的,但是由于传统软件构造架构的一些基本的能力限制,所以大部分这种互操作性的架构都发生在web之间,Web通过HTTP等协议提供了一些基本但相对比较复杂的互操作机制,大部分企业内部的业务之间都是基于网络传输协议来实现的微服务的形式构成的,这在某种程度上形成了一个复杂系统。此外,超链接URL使得互联网上的信息之间都可以连接起来,尽管它只是一个简单的链接,但是这些链接构成的信息背后的相关性构成了一些逻辑关系,使得它们也涌现出了智能,例如我们沿着这些链接可以寻找到很多很深层次有价值的信息,这些信息作为知识使得我们可以解决一些生活中的重大问题。
所以从这个角度看,构建一套新的软件构造的方法,使得人们可以更方便地去构造复杂系统形式的信息系统,这将带来帧数的数字智能的变革,这将使得计算的能力远远超越一般的逻辑计算。
计算的本质
在计算机和信息领域,我们理解的计算通常是指按照一定的逻辑和流程执行一些操作,编程语言定义了我们描述逻辑的方式,我们的逻辑用这种编程语言进行描述并形成代码程序,最后在计算机上被执行以完成这个计算。
然而当我们构建了一个具有复杂系统特性的信息系统的时候,这些涌现的能力是我们“计算”出来的吗?从这个角度看,可能计算的本质并没有那么简单。
在生物学、数学、统计学、物理学等跟复杂系统相关的科学领域,科学家一直在尝试为复杂系统寻找一些数学上的理论,复杂系统的视角至少从上个世纪50年代就已经在科学研究者中间被广泛思考和接受,例如著名的人工智能先驱 Herbert A. Simon 就是最早对复杂系统的架构进行分析的科学家,在他的著作《The Sciences of the Artificial》就大量使用复杂系统的视角来分析所有由人类参与的人工系统。他提出了一些构建这种系统的原则、方法和思维,比如通过目标、界面和环境的关系来描述人工系统,其中的界面其实就相当于子系统之间的边界,界面内部的就是内部功能,系统面对的外部环境就是其交互部分,而目标来源于进化论里面的选择。这些研究工作也为后来的复杂系统在工程上实施提供了许多宝贵的价值。
然而,最近几十年来,尽管随着生物学、物理、化学等学科的飞速发展给复杂系统的研究提供了很多依据,但是人们至今依然没有找到关于复杂系统的统一的数学理论。更多的研究者都偏向于复杂系统可能没有像其它自然科学一样具有比较明确的统一的数学理论。更多是从复杂系统的一些比较具有共性的一些特征去研究和使用复杂系统。
分子生物学John E Mayfield在他的著作《The Engine of Complexity: Evolution as Computation》中提出了一种关于复杂系统的解释,即将进化看作一种计算,这样计算就是所有复杂系统背后的引擎。这本书的 作者介绍 如下:
From an early age John E Mayfield was fascinated with science of all kinds. This broad interest led to a BA in physics, a PhD in biophysics, and an academic career in the area of molecular biology. In the late 1990s he was introduced to evolutionary computer algorithms and became fascinated by the relationships between biological evolution and computer based evolution and more generally in the linkages between computation and biological process. The Engine of Complexity, Evolution as Computation is based on his consequent studies. The book shows how biological evolution is a special case of a more general computational notion of evolution, and how that general view of evolution explains not only how life is possible but also how human technology and most or all complex outcomes of human society are possible. It is his first book.
John E Mayfield的主要研究方向是关于进化的一般性理论,他指出,传统的复杂系统之所以很难形成统一的数学理论,主要是因为系统之间交互关系是非线性的,而计算机的逻辑计算能力正是解决非线性关系的方法,且具有很强大表达能力,所以他发现将这两种视角结合在一起,用计算的观点就可以解释几乎所有复杂系统的机制。
作者指出,计算机程序是由能够导致计算机内部发生特定的状态序列并产生输出的命令组成。数据可以视为对外部世界某方面的表示,这样看来,计算就是将方法的表示(算法)作用于对世界某方面的表示(数据)产生内部表示(机器状态)的序列,并得到最终的表示(输出)。在计算机中,内部状态与输入状态互动产生新的内部状态,最终状态就是输出。
那么如果物理的过程也是计算,程序在哪?作者以如何解释一粒盐为例用计算的观点来解释化学反应,食盐是由钠和氯组成,当等量的钠原子和氯原子混合到一起,就会发生自发的反应,这个化学反应会释放热能量,每个钠原子失去一个电子,每个氯原子获得一个电子。根据库仑定律,带正电的钠离子和带负电的氯离子相互吸引,但不能距离太近,因为填充的能级(化学的轨道)不能相互渗透。当所有钠离子都被氯离子包围,氯离子也被钠离子包围,形成非常规则的3维结构,相抵触的规则时间就会达到最优平衡。能级的物理维度决定了例子之间的最优距离。钠离子和氯离子具有不同的大小,能平衡物理和几何不同需求的状态是一个规则的网格,每个氯离子周围有6个钠离子,每个钠离子周围也有6个氯离子。这个规则的立方体结构向各个方向延伸,从而形成我们所熟悉的盐晶。在适当的温度和浓度条件下钠离子和氯离子相遇就会自发形成这种结构。
在上述的过程中,涉及两个基本物理定律,一个是库仑定律,它说明电荷越接近,作用力就越大。但如果仅仅是这样,钠离子和氯离子就会挤碎在一起。而这一切没有发生是因为另一个量子力学中的被称为泡利不相容原理的规则。量子力学规则的一个特点是系统是按“能级”划分的,对于原子这意味着电子处于某个能级并且与质子的距离不能低于最低的能级。这种规则的结果是使得不同的能级只能占据一定数量的电子。
量子力学、库仑定律以及数字的相互作用赋予了每种化学元素独有的特征。John E Mayfield从计算的观点看,钠和氯原子各自带有自身表示的信息,当一定的条件发生时,它们会相互作用,发生相互作用的计算过程正是由基本的物理规则引起的,例如这里的库仑定律和量子力学规则,这些基础的物理规律编码了其中的计算算法。
按照这种视角,所有的进化系统或者复杂系统都可以用计算的观点进行解释。这种计算的视角对于我们构建软件计算架构最核心的意义在于,这种系统的计算是自动发生的,它没有某个中央控制器。在物理过程种,作者将物理规律在整个进化计算过程种充当的驱动自发计算的方式称为“免费的结构”,即我们自然界的所有基本的物理规则驱动着整个宇宙种复杂系统的计算。
回到我们的软件架构,我们已经具备了定义子系统以及让子系统之间进行互操作的能力,那么在没有中央控制器的情况下,怎样形成这种自发的子系统之间的交互呢?这就涉及我们的组件参数声明与全局变量之间的解耦,当我们的组件只是声明对某些数据感兴趣,而不需要自己去获取这些数据的地址的时候,借助我们的类型系统,系统就可以自动推导出它需要与哪些子系统进行交互,所以系统能够动态根据这种子系统之间的变化来决定这种交互东西,尽管系统在不还是有一个类似的分配器在工作,但是从组件或者子系统看来,这些子系统与其它子系统之间的交互是“自发的”,即:
- 子系统只需要声明自己感兴趣的数据,就像原子声明了自己的表示。
- 只要条件满足,子系统之间就可以进行交互,这个条件在物理过程中是自发进行的,在我们的系统中它也是自发进行的,因为系统会根据多个子系统之间的条件进行判断,满足条件的子系统之间就会被执行计算。
这里系统的调度充当了物理过程中那些物理定律对应的免费的结构,只不过我们不是像物理过程那样具有各式各样的物理定律来定义不同的结构,而是定义一个统一的规则,这个规则根据输入输出类型来计算交互的条件,而这些类型本身编码了各种各样的规则。
进化的系统
前面两节论述了复杂系统怎样通过多系统非线性和自发的的交互,来涌现整个系统的智能,以及我们的软件架构使用怎样的机制来支撑复杂系统的这种结构特征。
然而一个复杂系统是怎么形成的,这是另一个非常深刻的话题。传统的一个软件都是由某个公司内部大量的研发团队通过数个月以及数个不同职能的团队的协作共同完成的,它们的一个被认为理所当然以至于我们一般都不会去思考的特征是:一旦开发商发布产品,则意味着整个软件产品的功能全部开放完毕,从外界用户感知来看,他们一下子就开发出了一个功能确定且完整的产品。
在上述这样传统的软件产品中,我们一般认为它的业务逻辑是相对容易被开发团队理解的,因为尽管业务细节都带有很多复杂性,但是一个团队研发的某个软件产品在整体逻辑上处于某个特定领域,有一些特定的逻辑,因此其复杂度基本上都是在可管理的范围之内。但如前面所述,如果一个复杂系统作为一个整体,它的复杂度是很难被人理解和管理的,那么我们应该怎样去开发一个你甚至都不能理解整体功能的复杂系统产品呢?
回到前面电子购物的复杂系统,它呈现三个特征:
- 首先是每个子系统都是由独立的实体在开发及运行,这是复杂系统的基本特征;
- 其次是每个子系统内部都在独立迭代,例如交通子系统由火车到动车,由普通的公路到全国高速路网;物流公司由以前的长途配送,到增加最后一公里的送货上门,上门取件;
- 再次,整个系统中不断有新的子系统加入,这些可能是跟其它某些子系统功能相似但是处理不同类型任务的子系统,如新增不同的电商平台,以及新增快递公司;也可能是基于现有整体系统能力延升出来的处理新的类型业务的子系统,比如外卖就是一种不同于传统电商的服务类型,但它是基于在线购物和快递发展到一定成都时候才会产生的新的服务类型,及它的出现需要基于其它系统的演进。
从上面的过程我们可以看出,整个电子购物的复杂系统不是像传统软件那样一次性构建出来的,它们是进化出来的。所有复杂系统的功能演进都是一个进化的过程。
下面我们来分析我们的软件架构在一个进化系统的框架下是怎么工作的。根据《复杂的引擎》一书,所有进化过程的共同特征包括以下5个要素:
- 个体,它们一般有各种名字,比如:生物、自主体、基因、概念和公司。
- 可遗传的特征,个体的描述信息。以某种形式编码为个体本身的一部分,生物的这种信息编码为DNA。
- 个体可以繁殖或复制,通过这个机制,个体从父辈或之前的个体拷贝编码信息。
- 变化机制,信息在复制、繁殖或维护过程中必须有机会产生适应度的改变。在许多系统中变化机制就是复制过程中产生的错误。
- 基于特征的选择,繁殖(或复制)的成功必须部分取决于各个体编码信息所描述的特征。
只要系统同时具备了这5个要素,个体组成的群体中的编码信息以及相应的个体特征就会随着时间改变;遗传的个体特性也必然会越来越适应决定繁殖(复制)成功率的标准。
上述这是进化论中的知识,比如在生物的进化论中,生物个体携带DNA,其中编码了个体本身的特征,这些特征可以通过繁殖被复制到新的个体中,并且这个复制的过程中可以产生一定的变异,这种变异通常是随机的,进而形成一些新的特征,这些新的特征能否被保留下来,取决于自然选择,即它能不能具有更大的优势保障个体的生存。具有这种逻辑结构的系统会累积适应选择标准的编码信息。在自然和生物系统中,它们通常利用随机变化做到这一点,有时候也会利用非随机变化,以免偶然性过大,不利于产生有用或有趣的东西。因此这个信息累积和改进的过程就是概率计算,它有效的原因很简单,很小的变化通常是有可能的,而无目的的大变化基本不可能发生,通过小的并非很不可能的变化,并累积好的变化,就有可能达到本来很难达到的目标。
进化论的思想几乎可以解释一切生物和大自然的复杂系统,但如果直接将这一套方式作用于我们的软件开发则是不合适的,首先完全依赖于随机变化的效率会比较低,其次通过漫长的自然选择则会使系统的演进很慢,想想我们人类的智力演进是多么漫长的一个过程。
因此我们必须保留进化论的精髓,同时要在效率部分做出不同的处理。下面分析我们的架构其中包含的进化思想。
对于计算机,进化的信息是软件代码。我们来看在我们的系统中怎样对应和解释这5个要素:
个体:就是包含了自身功能代码的各个子系统,例如一个智能体(Agent)程序。
可遗传的特征:我们的代码显然像DNA编码了生物个体特征意义,它编码的整个程序的特征(功能),很显然,代码是可以复制和遗传的。
个体可以繁殖或复制:你只要复制了另一个智能体的代码或者说你的系统以某种方式可以包含或者调用另一个子系统的代码,其实这在软件中也是一种形式的复制。
变化的机制:生物或自然系统的变化机制主要是靠随机过程,它主要体现在对编码信息的部分随机修改。我们的软件系统显然不是对已有的程序去添加一些随机的修改,因为那样的程序大部分情况下根本就无法运行。我们的随机性主要来源于一个新的开发者像一个已有的程序中添加部分能够修改程序行为的代码,举个例子,原来的程序包含A组件,现在借助我们的互操作性,这样的程序可以很方便与其它程序进行交互,现在有另一个开发者开发了一个能够与A组件进行互操作的程序,然后某个用户同时购买了A和B两个组件,那么它们整体看就是产生了变化。所以我们的子程序之间的互操作性,以及函数级的可组合性,这些都是变化的机制,我们后面会详细介绍其中的技术细节。
在传统的软件中,我们也可以对已有的软件进行修改,从而实现类似上面这种变化。但是因为传统的软件只是对开发商内部是公开的,所以只有一个很小的团体能够改进软件,这就会使得软件的变化的概率非常小,甚至在某个程度之后停止变化,因为这个开发商的研发人员数量在整个人类完全是可以忽略的。而在一个开放的软件时间,这样的变化是完全不受限制的,因此进化的概率更大,更有可能进化出完全意想不到的结果,因为这里面能够导致变化的开发者人员的数量基数是非常大的,后面我们也将详细分析我们怎样通过简化程序结构来使得更多的非程序员可以编写程序。
基于特征的选择:这些变化出的机制是否有效,取决于它们是否适应和满足人们的某些目标。所以当这些变化发生之后,新的子系统会产生,然后会有一部分用户有机会是使用这些新的子系统,在使用过程中,如果这些子系统很好地解决了人们对数字世界的一些需求,那么它们就会被选择,即它们适应了选择,否则这样的新的子系统则会很快被淘汰。
这种选择机制在软件的消费中倒是非常有效,但是这种方式显然还没有真正促进软件大规模的进化,例如看看我们手机里的应用及其形态,大部分的应用已经有很多年没有太大的进化了,而相反,我们的数字世界的功能也没有变得非常的丰富和智能。这种缓慢的进化与两个要素有关,一是上面讲到的变化的缓慢,二是跟这里的选择机制有关,即人们其实没有太多选择,就导致选择并没有在整个系统中表现出很强的力量。
现代的软件都累积了很多的功能,用户要么购买及使用整个软件,要么就使用不了软件,大部分情况下我们必须要使用其中的核心产品功能,所以不得不安装,但是其中包含的大量功能我们完全无法选择,因为没有选择这也会导致开发商并没有那么大的选择压力。
我们的系统是一个完全动态的系统,用户可以选择完全不同的子系统组合,这也就意味着用户对每个很小的子系统有很高效的选择机制,这就会催生一个完全不同效率的进化系统。在我们系统架构中,动态性和互操作性在遗传、变化和选择这三个重要的进化要素中都发挥了重要作用,从而整体呈现出更高效的进化效率。通过这种进化的力量,演进出复杂的系统功能,从而使数字世界表现出更加智能、复杂和丰富。
外在结构和内在结构
前面我们从互操作和复杂系统机制的层面对RealityIS的架构哲学进行了一些介绍,在了解这两个部分的内容之后,我们再来系统地梳理一下其中的逻辑,使我们对整个系统架构有更清晰的认识。
从整体看,RealityIS的两个设计目标或特性是:
- 互操作性
- 自我进化
所有的技术思想和对现有技术的改进思路都是围绕上述两大目标的,其中互操作性解决的问题是要让任何子程序能够非常轻易地跟外界通信和交互,这既是复杂系统结构所需要的基本特性,也是实现一个广泛相互协作而繁荣的数字经济的基础,想想我们现实世界人与人、实体与实体、人与社会等各种关系都是有非常广泛而深刻的交互的,在计算机的世界,交互就是互操作。
自我进化,是复杂系统构建和演化的核心机制,我们不是一次性通过某个实体就开发了整个系统的功能,而是通过子系统之间的相互协作来进化出各种更复杂的功能,对应的软件开发的过程中,这要求系统具有非常动态的能力,能够动态地新增或者删除子系统,同时也要求这些子系统之间具有自治的能力,这样系统才能自发地进行进化,而不需要全局干预。
围绕着两个目标,我们发现传统的软件构造体系根本就是跟这两个目标相悖的,这主要体现在:
- 数据与代码的耦合使软件失去了互操作性,同时也造成了中心化治理的结果
- 局部代码在获取决策上下文时与全局信息的耦合使软件失去了自治的能力
针对这两个问题,我们分别从区块链和复杂系统理论中寻找到对应的理论支持,使我们可以获得一个非常简洁、干净、稳定、而又功能强大的技术架构。它们形成整个技术架构的两个结构,我们称之为外部结构和内部结构,如下图所示:

针对互操作性,我们从区块链中得到启示,尽管不是很直接,但是它为了实现去中心化采取的将数据与计算分离,并在虚拟机中在运行时对数据进行授权的技术流程,被我们很巧妙地用一套动态的类型系统进行一般化,使之能够支持更广泛的数据类型,同时又能确保用户的数据安全。这样的调整使得我们完全实现了互操作性,这种互操作性不光使得不同开发者开发的应用程序可以在一些协同计算,相互交互,更重要的是为复杂系统的构建奠定了基础:这样一个系统的功能有机会被多个自治的子系统进行融合而形成,而不是仅仅只有一家开发商构建,那样其能提供的功能的复杂度将会远远低于复杂系统。我们称这些由互操作性带来的结构为外部结构,它反应的是子系统与外界交互的能力。
针对自我进化,我们从复杂系统的理论中得到启示,其核心的思想是自治能力,即子系统可以在不经过中央或者全局控制的情况下实现局部子系统之间的交互,因为这种交互不光带来安全隐患,还使得子系统可能会受限于中央控制器而不容易去单独扩展能力,而这是进化系统的基础。为了解决这个我们,我们从游戏开发界最新的ECS架构得到启示,并结合我们的动态类型系统,实现一个基于类型的局部自治架构,在这样的架构中,子系统只需要声明关注的数据类型,即可以定义与其它子系统之间的交互关系。围绕这些机制,我们还进一步分析了整个系统的进化过程,它遵循生物或自然界中复杂系统进化相似的原理或过程。我们称这部分结构为内在结构,它决定着一个子系统内部怎样去演进和进化。
在内部结构和外部结构之外的系统中,用户则牢牢掌握着所有的数据权限,并通过数据权限控制着整个程序的运行,包括一个子系统是否可以访问用户的某些数据,以及一个子系统是否可以与其它子系统进行交互,甚至一个子系统即使已经被用户安装到用户的应用环境,它仍然可以通过数据被完全禁止运行。用户对数据的权限被牢牢地集成到系统的虚拟机中,
RealityIS系统架构
对互操作性的改进:
- 由调用过程获取结果,变为直接获取其过程,即将被调过程执行的结果存储在一个语义数据,这样就是一个类型或者数据本身包含了互操作性,就简化为数据管理的问题(游戏中的机制)
构建一个动态类型系统
两个目的:
- 类型解析,做依赖分离
- 数据和功能分离,通过类型的解析控制,来阻止未授权程序的访问,当然实际不是运行到某个函数时在检查,而是组件可以根据类型信息提前检查出来
动态授权很重要,如果没有这个控制,只是在Actor之间传递字符串,意味着某个Actor被执行,就无法控制它访问数据。
建立一个互操作抽象
逻辑抽象,不涉及编程语言与编译器开发
简化数据获取
简化程序结构
复杂系统:由主动到被动自动运行
局部驱动
应用由主动执行到被动持续执行,跟用户的主动输入不是同步的,可能是自动执行的,用户怎么感知系统变化状态
应用由主动执行到被动持续执行,跟用户的主动输入不是同步的,可能是自动执行的,用户怎么感知系统变化状态
非中心化的系统交互
虚拟机
字节码
本质上结构跟Wasm相似,可以做到很底层,都是函数级的数据,只是函数调转的机制不一样。
{
"magic": "0",
"version": "1.0.0", // VM的版本号,类型的解释方法一般不变
"inputs": [ // 内部Standard格式可能存在和用户版本不兼容,运行时检查
{
"User":{
"version": "1.0.0",
"name": "String",
"age": "int"
}
}
],
"standards":[
"Car":{
}
]
"components": [
{
"name":"add_com",
"inputs":[
"User"
]
"output":[]
}
], // 内部方法
"outputs": [], // 可能存在版本不兼容
"codes"" [] // 将所有代码放在一起,Component还有其它参数信息影响缓存连贯性
}
inputs
将属性定义都拷贝进Agent内部,一是方便Agent编辑,同时考虑到后面Component的参数签名是跟Standard的属性名字绑定的,并没有像传统编译器那样编译为地址,例如:
{
"inputs":[
"User":{
"version": "1.0.0",
"name": "String",
"age": "int"
}
]
}
但是运行时检查到版本不一致时,自动做一些转化。
Standard版本兼容
为了避免不断的更新,实行两个策略:
- 小版本必须兼容
- 大版本必须更新Agent,否则不让运行
小版本兼容
- 修改字段名字
大版本更新
- 增加字段
- 删除字段
- 修改字段类型 = 删除字段 + 增加字段
Lua与宿主交互
类型解耦,
Python没有Lua那样的动态类型,先支持Lua
RealityIS技术特征
执行流程
传统几种模式:
函数调用关系
实际上是转化为程序的传统结构
- 需要管理函数实例及其地址
- 需要关系参数的链接
流程顺序
Hodini的方式
- 不用管理函数实例
- 按类型名字进行获取数据
ShadeGraph
- 管理依赖关系
- 依赖关系由变量名称确定,即是类型的实例,即是参数的连接,只不过定义了全局参数,而不是从函数的输入输入去连
变量名字不易于复用
// Create the graph - it starts out empty
cudaGraphCreate(&graph, 0);
// For the purpose of this example, we'll create
// the nodes separately from the dependencies to
// demonstrate that it can be done in two stages.
// Note that dependencies can also be specified
// at node creation.
cudaGraphAddKernelNode(&a, graph, NULL, 0, &nodeParams);
cudaGraphAddKernelNode(&b, graph, NULL, 0, &nodeParams);
cudaGraphAddKernelNode(&c, graph, NULL, 0, &nodeParams);
cudaGraphAddKernelNode(&d, graph, NULL, 0, &nodeParams);
// Now set up dependencies on each node
cudaGraphAddDependencies(graph, &a, &b, 1); // A->B
cudaGraphAddDependencies(graph, &a, &c, 1); // A->C
cudaGraphAddDependencies(graph, &b, &d, 1); // B->D
cudaGraphAddDependencies(graph, &c, &d, 1); // C->D
到目前为止cuda graph的依赖需要用户手动设置。当kernel或其他操作输入变量变化时,cuda graph需要用户手动更新节点参数。
当我们面对大量节点与输入参数时,手动来构造cuda graph和更新节点就不太现实,于是muda自动计算图就应运而生了。
在1)部分我们定义了graph var,这些graph var在muda compute graph中只表示一种虚拟资源(muda compute graph 默认所有的虚拟资源相互之间不产生重叠,即内存不发生overlap)。一般我们会要求图的输入变量为一个viewer(他本身不拥有资源,只是一个资源的访问器,是trivially copyable的),或是一个值类型。如果你知道你在干什么,那么你也可以使用奇技淫巧。
在2)部分,我们定义了graph nodes。注意,graph nodes的定义顺序会影响graph nodes的依赖关系,graph nodes的定义顺序应该是所有任务的逻辑顺序,这非常的intuitive!我们的所有串行代码都是这么写的。
Cogine
从上述的方案中总结:
- 要想简化,都需要全局数据,不管是Houdini中的几何数据,还是ShaderGraph中由变量名字确定的全局数据,这样避免牵涉对函数细节的了解
- 流程比实际的函数调用更简单,如Houdini和ShaderGraph
- 用户理解流程很重要,相比由输入输出来确定参数不太利于管理和控制,比如你要修改流程就必须去修改变量名字;相同的流程在一个系统中多次执行则要定义不同语义的变量名字
像ShaderGraph通常是固定的流程,没有Control FLow,即每个流程都会被执行,并且通常能被计算出一个线性的执行顺序使其可以保证其中定义的依赖关系。
互操作性
可组合性
传统两种组合方式,一种是单纯对象级别的组合,例如Unity的Component,一种是函数式编程中的组合,通过高阶函数
个性化
动态性
分布式
语义化
组件化
被动式
被通知,持续运行
应用
挑战
技术挑战
动态类型带来的性能问题
改进语言虚拟机,去掉函数栈等控制的机制,仅保留代码执行
编译为像WASM的字节码,WASM本身就是按函数级定义的,其实我们的机制正是对应这种,只不过函数换成我们的组件
程序的持续运行模式
对涌现能力的预测
类似于游戏测试
可能很多人的经验和知识在于去控制和发现这种结构,然后筛选出更有价值的结构,这就是进化论里面的选择。
智能必须依赖于较大的突变和选择,较大的突变必须要有条件能够生产非常多错误的结果。
用户体验挑战
用户从功能管理到数据管理
启示这已经比较普遍,只是管控的是API,但是API代表的就是一种数据的获取,
应用由主动执行到被动持续执行
跟用户的主动输入不是同步的,可能是自动执行的,用户怎么感知系统变化状态
我们需要被通知,而不是一个我要做什么的数字世界
动态的数字世界
人天生就是使用观察动态世界的,只是你要给出合适的方式,比如尤其是考虑到屏幕的交互,以及数字世界的信息量远多于现实世界
例如股票就是这样
传统的数字世界都是一致的,而且事实证明用户在使用一个新应用的时候,新应用带来的阻碍都很大的,不管是认知、体验、交互等等
所以需要一致的交互体验,大模型对话式的交互方式可以大大简化传统GUI方面的复杂度和丰富性,比如小程序就是一种类似的体验,虽然应用内容不一样,但是用户使用新的应用的流程比较一致,所以并没有造成太大的阻碍。
当然用户也不是一直在换,大体说很长一段时间还是稳定的,但是社会发现有新的有价值的应用时传播得会更快。
少量的比较追踪科技的用户则会更习惯这种能够快速体验到新产品的节奏和感觉。
展望
驱动硬件创新
驱动软件架构创新
驱动数字形态创新
驱动操作系统创新
总结
未来可能类型系统和数据集成到操作系统或手机本地的基础设施
或者一个或多个分布式系统,但总归分布式系统的能力是更强大的,操作系统支持会简化数据的管理